deductor платформа данный визуализация
На сегодняшний день в мире работают сотни миллионов персональных компьютеров. Ученые, экономисты, политики считают, что к началу третьего тысячелетия: количество компьютеров в мире сровняется с числом жителей развитых стран; большинство этих компьютеров будет включено в мировые информационные сети; вся накопленная человечеством к началу третьего тысячелетия информация, будет переведена в компьютерную форму, а вся информация будет готовиться при помощи компьютеров; вся информация будет бессрочно храниться в компьютерных сетях.
С появлением вычислительной техники, значительно упростились способы хранения, передачи и обработки информаций.
Для принятия обоснованных и эффективных решений в производственной деятельности, в управлении экономикой и в политике современный специалист должен уметь с помощью компьютеров и средств связи получать, накапливать, хранить и обрабатывать данные, представляя результат в виде наглядных документов. В современном обществе информационные технологии развиваются очень стремительно, они проникают во все сферы человеческой деятельности.
Современный уровень развития аппаратных и программных средств с некоторых пор сделал возможным повсеместное ведение баз данных оперативной информации на разных уровнях управления. В процессе своей деятельности промышленные предприятия, корпорации, ведомственные структуры, органы государственной власти и управления накопили большие объемы данных. Они хранят в себе большие потенциальные возможности по извлечению полезной аналитической информации, на основе которой можно выявлять скрытые тенденции, строить стратегию развития, находить новые решения.
Поэтому нахожу актуальным на сегодняшний день уметь обрабатывать информацию и визуализировать данные в графически понятном виде для возможности последующего выполнения анализа и принятия правильных решений.
В настоящее время в комплексе современных инструментальных средств, обеспечивающих поддержку бизнеса, значительную роль играют аналитические инструментальные средства. Развитие инфраструктуры компании и спектр решаемых аналитических задач зависит от уровня зрелости организации, ее стратегических и тактических целей, а также степени подготовки специалистов и их мотивации для использования инновационных технологий.
В условиях сложной экономической ситуации становится актуальным обеспечение специалистов предприятий малого бизнеса автоматизированным инструментарием оперативного принятия управленческих решений. Оперативное принятие управленческих решений, адекватных изменяющимся условиям экономической и социальной среды, позволит гибко управлять хозяйственной деятельностью предприятия малого бизнеса.
Исследовательская работа «Бизнес» проект по обществознанию (7 класс)
... разделы бизнес-плана, которые содержат информацию, направленную на реализацию целей бизнес-планирования. Основными элементами бизнес-плана являются: 1.вводная часть (резюме); 2.содержательный раздел (описание, сущность проекта); 3. разделы внутрифирменного планирования (деятельность и ...
В социуме присутствует такая важная общая характеристика, как самоорганизация — одна из форм синергизма. Обобщающий взгляд, характерный для синергетики, обладает большой эвристической ценностью при анализе таких явлений, как «экономика, основанная на знаниях» (knowedge-based есоnоmу, инновационная экономика), экономические катастрофы и ряд других. Основой современной «новой экономики» представляется инновационный взрыв в сфере информационных технологий (компьютеры, программное обеспечение, телекоммуникации и Internet).
Использование новых информационных технологий: методов искусственного интеллекта, компьютерных средств когнитивного моделирования и т.д., открывает новые возможности специалистам предприятия малого бизнеса. Включение представления знаний в автоматизированную систему искусственного интеллекта рассматривается во взаимосвязи с качественными и количественными параметрами когнитивной модели с позиций синергетики.
Управление знаниями рассматривается как совокупность процессов, управляющих созданием, распространением, обработкой и использованием знаний в рамках организации. Технологической основой систем управления знаниями являются хранилища данных. Анализ информации в хранилищах данных базируется на технологиях интеллектуального анализа данных, целью которого является извлечение знаний из накопленных данных за некоторый промежуток времени.
Таким образом, появляются новые технологии организации, хранения и обработки экономической информации. Примером таких технологий являются так называемые Business Intelligence средства, предоставляющие конечному пользователю возможности доступа и последующего анализа прикладных структурированных данных с целью прогнозирования и принятия решений в сфере экономики и бизнеса.
К средствам Business Intelligence относятся хранилища данных Data Warehouse, генераторы отчетов и средства аналитической обработки. OLAP, а также средства поиска закономерностей — Data Mining. Business intelligence средства (или искусство преобразовывать данные в знания) являются одним из аспектов управления знаниями. Вышеуказанные средства в полной мере реализует аналитическая платформа Deductor.- аналитическая платформа, основа для создания законченных прикладных решений в области анализа данных. Реализованные в Deductor технологии позволяют на базе единой архитектуры пройти все этапы построения аналитической системы: от консолидации данных до построения моделей и визуализации полученных результатов. До появления аналитических платформ анализ данных осуществлялся в основном в статистических пакетах. Их использование требовало высокой квалификации пользователя. Большинство алгоритмов, реализованных в статистических пакетах, не позволяло эффективно обрабатывать большие объемы информации. Для автоматизации рутинных операций приходилось использовать встроенные языки программирования. Стремительный рост объемов информации, накапливаемый на машинных носителях, привел к возрастанию потребности бизнеса по анализу массивов данных.
Результатом запроса стало появление хранилищ данных, машинного обучения, Data Mining, Knowledge Discovery in Databases, что позволило популяризировать анализ данных и решить некоторые бизнес задачи с большим экономическим эффектом. Венцом развития анализа данных стали специализированные программные системы — аналитические платформы, которые полностью автоматизировали все этапы анализа — от консолидации данных до эксплуатации моделей и интерпретации результатов. Первая версия Deductor увидела свет в 2000 г., и с тех пор идет непрерывное развитие платформы. В 2007 г. выпущена пятая по счету версия системы, в 2009 г. — версия 5.2. Сегодня Deductor — это яркий представитель как настольной, так и корпоративной системы анализа данных последнего поколения.
Методы сбора данных для анализа социально-экономических и политических процессов
... людьми и т. д. 1.1 Контент-анализ как метод исследования Для сбора географической, экономической, демографической, исторической, культурной информации, данных о политической ситуации не обойтись без анализа различных статистических сведений. Они могут ...
Глава I. ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
1 Описание платформы Deductor
Организации накапливают огромные массивы данных, однако не в состоянии получить от этой работы реальную отдачу. Имея исторические данные, можно решить критически важные для бизнеса задачи: оптимизировать процессы, управлять рисками, повышать доходность, удерживать клиентов…
Для таких задач не достаточно визуализации: отчетов, OLAP, информационных моделей — пользователи тонут в горах графиков. Для получения реальной отдачи нужно использовать методы глубокой аналитики (Data Mining), позволяющие не только просмотреть диаграммы, но автоматически находить закономерности, строить прогнозы, выявлять аномалии, т.е. помогать делать выводы.- аналитическая платформа, в которой реализованы технологии позволяющие решить весь спектр задач полноценного анализа данных от консолидации и отчетности до прогнозирования и оптимизации.
2 Назначение
Решения на базе Deductor, позволяют пользователям быстро принимать обоснованные управленческие решения, благодаря реализации полного цикла аналитической обработки:
Консолидация данных из десятков разнородных источников
Очистка, систематизация и обогащение собранной информации
Отчетность, визуализация, OLAP-анализ, расчет KPI
Моделирование, прогнозирование, оптимизация
Самообучение на новых данных и адаптация моделей
3 Преимущества платформы Deductor
Для руководителя:
- минимизация затрат: любая аналитика — одна платформа;
- эволюционное развитие от простой отчетности до сложной оптимизации;
- апробированная платформа — сотни проектов со сложной аналитикой;
- десятки партнеров, тысячи обученных специалистов.
Для аналитика:
- полный спектр технологий анализа: Data Warehouse, ETL, OLAP, Data Mining, KDD;
- аналитика от простых формул до самообучающихся алгоритмов;
- модификация логики анализа без привлечения программистов;
- поддержка: система дистанционного обучения, кейсы, отраслевые курсы.
Для IT-специалиста:
- встроенная интеграция с десятком источников данных;
- высокая производительность;
- техническая поддержка непосредственно от разработчиков.
4 Организационная структура аналитической платформы Deductor
Аналитическая платформа Deductor состоит из пяти частей:
- Warehouse — хранилище данных, консолидирующее информацию из разных источников;
- Studio — приложение, позволяющее пройти все этапы построения прикладного решения, рабочее место аналитика;
- Viewer — рабочее место конечного пользователя, одно из средств тиражирования знаний (т. е. когда построенные аналитиком модели используют пользователи, не владеющие технологиями анализа данных);
- Server — служба, обеспечивающая удаленную аналитическую обработку данных;
- Client — клиент доступа к Deductor Server.
Обеспечивает доступ к серверу из сторонних приложений и управление его работой. Разработчиками представляются три типа аналитической платформы Deductor: Enterprise; Professional; Academic. В нашем случае представлен пакет Academic. Версия Academic предназначена для образовательных и обучающих целей. Ее функционал аналогичен версии Professional за исключением:
Методы анализа и обработки данных
... развитии. В данной работе анализируются способы и методы анализа и обработки данных. Основная цель экономического анализа – получение наибольшего числа ключевых параметров, дающих объективную ... материальных, трудовых и финансовых ресурсов. Можно выделить следующие основные принципы анализа и обработки данных: Научность – базируется на положениях динамической теории познания, учитывать требования ...
- отсутствия пакетного запуска сценариев, работа в программе может вестись только в интерактивном режиме;
- отсутствия импорта из промышленных источников данных: 1С, СУБД, файлы MS Excel, Deductor Data File;
- также недоступны некоторые другие возможности.
Версия Enterprise предназначена для корпоративного использования и имеет расширенный потенциал.
Версия Professional предназначена для небольших компаний и однопользовательской работы. В ней отсутствуют серверные компоненты, поддержка OLE, виртуальное хранилище, а традиционное хранилище данных можно создавать только на СУБД FireBird. Автоматизация выполнения сценариев обработки данных осуществляется только через пакетный режим.
аналитик;
- пользователь;
- администратор;
- программист.
Студенты могут выступать в качестве аналитиков и пользователей аналитической платформы. Функции аналитика:
- создание в Deductor Studio сценариев — последовательности шагов, которую необходимо провести для получения нужного результата;
- построение, оценка и интерпретация моделей;
- настройка панели отчетов для пользователей Deductor Viewer;
- настройка сценария на поточную обработку новых данных.
Функция пользователя — это просмотр готовых отчетов в Deductor Viewer.Состав и назначение модулей Warehouse — многомерное хранилище данных, предназначенное для решения задачи консолидации информации. Использование единого хранилища позволяет обеспечить простой и прозрачный доступ к данным, контроль целостности и непротиворечивости информации, высокую скорость обработки. Благодаря глубокой степени интеграции любую информацию из хранилища данных можно получить в приложениях Deductor с минимальными усилиями. Хранилище данных ориентировано именно на аналитическую обработку, поэтому включает в себя все, что необходимо для комфортной работы при анализе. Оно содержит интегрированный семантический слой, то есть механизм, автоматически преобразовывающий бизнес-термины в операции с базой данных и обратно. Благодаря наличию семантического слоя пользователь оперирует такими бизнес-понятиями, как «клиент», «товар», «прибыль», а система автоматически выполняет необходимые действия c базой данных и предоставляет пользователю нужную информацию. Применение хранилища данных позволяет не быть привязанным к учетной системе, хранить данные не только за последний период, а за весь необходимый для анализа срок, консолидировать информацию из разнородных источников. Использование специализированных методов хранения и извлечения данных значительно увеличивает скорость получения информации. Хотя наличие единого источника данных не является обязательным условием работы аналитической системы, практически всегда ее создание начинается с построения хранилища данных. Warehouse поддерживает прозрачную работу с тремя СУБД: Firebird, MS SQL и Oracle. Вне зависимости от используемой СУБД работа с хранилищем происходит совершенно одинаково с использованием единого унифицированного механизма доступа. Поддержка нескольких СУБД в качестве платформы хранилищ, данных позволяет в каждом конкретном случае применять наиболее пригодную для данного случая базу данных. В нашем случае используется бесплатное (FireBird) программное обеспечение. Кроме того, в Deductor реализована поддержка концепции виртуальных хранилищ, данных — Virtual Warehouse. Виртуальное хранилище данных обеспечивает прозрачный для аналитика доступ к сведениям, хранящимся в любых реляционных СУБД. Взаимодействие с Virtual Warehouse происходит аналогично работе с традиционным хранилищем данных. Аналитик оперирует бизнес-понятиями, заданными в семантическом слое, и от него скрыты все сложности выборки данных, как и в случае с Deductor Warehouse. Пользователь задает при помощи простого Мастера, какая информация его интересует, а система автоматически трансформирует их в запросы к базе данных. Таким образом, эмулируется работа хранилища данных, а данные реально не перегружаются в специализированную систему, все операции производятся «на лету». Virtual Warehouse позволяет представить информацию, хранящуюся в реляционных базах данных, в удобном для аналитика многомерном виде. Deductor Studio — это рабочее место аналитика. В этом приложении осуществляется формализация знаний эксперта. Программа включает все необходимые для анализа инструменты обработки: механизмы импорта данных из разнородных источников, методы очистки и предобработки, алгоритмы построения моделей и механизмы экспорта данных.
Создание хранилища данных
... хранения используются концепция хранилищ данных (ХД). В основе концепции хранилищ данных лежит идея разделения данных, используемых для оперативной обработки и для решения задач анализа, что позволяет оптимизировать структуры хранения. Хранилище данных позволяет интегрировать ранее ...
Все действия по анализу данных сводятся всего к 4 операциям:
- Импорт данных.
В процессе импорта данные получаются из источника и загружаются специальным образом в программу. В дальнейшем с ними можно производить любые доступные операции, работа со всякой импортированной таблицей происходит одинаково. Поддерживается импорт из наиболее распространенных СУБД (Oracle, MS SQL, MySQL, Interbase…), стандартных файлов обмена данными (dbf, txt, csv…), офисных приложений (MS Excel, MS Access…), бизнес-программ (1C v7, v8…).
Кроме того, в программу встроен механизм импорта с применением стандартов доступа к данным ODBC и ADO.
- Обработка данных.
Обработкой называется любое действие над данными, приводящее к их преобразованию, например, очистка данных либо построение моделей. Ее результатом является набор данных, который можно опять обработать каким-либо способом. Благодаря этому обеспечивается возможность построения сценариев обработки, то есть последовательных операций над данными, приводящих к нужному результату. Поддерживается широкий набор механизмов обработки: методы очистки (заполнение пропусков, редактирование аномалий, фильтрация…), инструменты предобработки (квантование, группировки, сортировки…), методы построения моделей (нейронные сети, самоорганизующиеся карты, деревья решений…).
- Визуализация.
Полученные результаты можно просмотреть различными способами, начиная от простых таблиц и диаграмм до многомерных кубов и специализированных визуализаторов. Система построена таким образом, что самостоятельно определяет возможные способы визуализации и предлагает наиболее удобные способы отображения данных для каждого случая.
Обмен данными в приложениях OC Windows
... любое преобразование, в том числе и формата, влечет за собой потери. Многие специалисты считают конвертирование частным случаем более общей операции – импорта-экспорта данных. В этом действии данные одного файла-документа ... Если такая информация не поступила, фрагмент сохраняется в буфере до окончания сеанса работы Windows. Запуск и завершение программ сами по себе на содержимое буфера никак ...
- Экспорт данных.
Результаты обработки могут быть выгружены во множество приемников данных. Таким образом, обработанная и проанализированная информация выходит за пределы аналитической платформы, попадает в бизнес-приложения, офисные программы и прочее. В Studio реализованы самые современные самообучающиеся алгоритмы анализа. Анализ данных в Deductor Studio базируется на построении сценариев обработки.
Алгоритм типового сценария представляется
- аналитик загружает анализируемые данные в Excel или, в нашем случае, в текстовый редактор;
- производит операцию импорта;
- проверяет данные на наличие ошибок и исправляет их, например, продажи с нулевой суммой или возврат товара поставщику, этот процесс называется операцией очистки;
- группируются данные для получения итоговой информации по месячным продажам определенного товара — это операции трансформации;
- аналитик подбирает модель полинома или другую формулу, которые объясняли, исторические продажи — это этап построения модели;
- применяется построенная модель для получения прогноза на следующий период, реализуется процесс прогнозирования;
— последний этап анализа — отправка результатов прогноза заинтересованному лицу. Этот процесс реализуется экспортом полученных результатов. Работая с Deductor, аналитик строит сценарий по описанному алгоритму. Studio не имеет механизмов ввода и ручной правки данных. В случае, если аналитик, получив данные, обнаружит в них, например, ошибки, он должен будет описать правило работы с такими данными. Например, он должен будет отфильтровать данные о продажах с нулевой суммой. Это является обязательной операцией, так как вручную в Deductor Studio удалить непригодные записи невозможно. То, что он сформулирует, автоматически станет частью сценария. Такая работа требует чуть больше усилий и времени, чем простое удаление данных из таблицы, но подобный сценарий обработки тиражируем. При появлении новых данных не нужно опять искать некорректные записи, а воспользоваться правилом их обработки в сценарии, и очистка данных может быть выполнена автоматически. Эта особенность позволяет говорить о Deductor как об инструменте тиражирования знаний.

В Deductor сценарии отображаются в виде дерева с иконками и пояснительным текстом (рис. 1.) Взглянув на это дерево, можно без труда проследить логику сценария и понять особенности его реализации. Это помогает не только модифицировать сценарии, но и передавать их другому аналитику, который также просто сможет «прочесть» ход мысли аналитика, создавшего сценарий. Анализ не ограничивается только обработкой данных, визуализация данных позволяет значительно повысить результативность анализа. В системе имеется множество удобных способов отображения данных. Программа самостоятельно анализирует способы обработки, особенности набора данных, на которых производился анализ и автоматически предлагает возможные способы визуализации. Среди множества механизмов визуализации, встроенных в Deductor Studio, имеется и мощный Online Analytical Processing (OLAP) модуль. OLAP — один из наиболее популярных способов отображения табличных данных. Данные в этом случае могут отображаться в виде кросс-таблиц или кросс-диаграмм. Кросс-таблицы удобны тем, что большая часть операций манипулирования данных выполняется «на лету». Одним щелчком мыши, можно данные сгруппировать произвольным образом, отфильтровать, отсортировать, переставить столбцы/строки и произвести множество других операций. Deductor Studio позволяет при помощи этого механизма визуализации просмотреть любые данные, т. е. не только саму исходную информацию, но и результаты любой обработки. Studio — это инструмент аналитика, а он является ключевым лицом в процессе анализа данных, именно его знания формализуются и тиражируются, но многие пользователи не являются аналитиками, для них нужен более простой и понятный способ получения требуемой информации. В Deductor Studio имеется панель отчетов, напоминающая проводник в известных операционных системах. На этой панели аналитик формирует иерархическую структуру папок и в определенные папки выносит ссылки на интересующие пользователей узлы сценария. Viewer — это рабочее место конечного пользователя. В нем отсутствуют механизмы построения сценариев, настройки источников, данных и прочие сложности. Работа с программой упрощена до предела: пользователь видит настроенную аналитиком панель отчетов, выбирает интересующий отчет, программа автоматически выполняет все необходимые действия, и конечный пользователь получает результат. Эта составляющая является частью более расширенных видов аналитической платформы и в нашем случае не применяется, впрочем, как и Deductor Server/Client. Server функционирует в виде Windows-службы, к которой можно обращаться удаленно при помощи специального клиента — Deductor Client. Управлять выполнением сценарием можно как из локальной сети, так и через Интернет. Использование Deductor Server значительно упрощает создание полноценной корпоративной аналитической системы, его применение позволяет воспользоваться всеми преимуществами трехзвенной архитектуры, оптимально используя возможности серверной аналитической обработки.
Глава II. ПРАКТИЧЕСКАЯ ЧАСТЬ
1 Принципы работы
Импорт данных
Анализ любой информации в Deductor начинается с импорта данных. В результате импорта данные приводятся к виду, пригодному для последующего анализа при помощи всех имеющихся в программе механизмов. Природа данных, формат, СУБД и прочее не имеют значения, т.к. механизмы работы со всеми унифицированы. <#»774066.files/image002.gif»> <#»774066.files/image003.gif»>
- Рис. 2. Схема работы Deductor Studio
Studio позволяет аналитику автоматизировать рутинные операции по обработке данных и сосредоточиться на интеллектуальной работе: формализация логики принятия решений, построение моделей, прогнозирование. Остальные сотрудники компании могут легко воспользоваться готовыми результатами, не вникая в сложности анализа:
Аналитическая отчетность. Аналитик перетаскивает мышкой на специальную панель необходимые отчеты. Конечный пользователь при помощи Deductor Viewer просто выбирает интересующий отчет из списка и получает результат. Никаких дополнительных действий делать не требуется. Вся сложная аналитическая обработка выполняется автоматически.
Интеграция в бизнес-процесс. Аналитик экспортирует результаты в стороннюю систему: сайт, ERP, CRM и т.п., а конечный пользователь увидит в привычной ему программе итог сложной аналитической обработки. Обмен данными может производиться в режиме online или по регламенту. Для встраивания в бизнес-процесс необходимо воспользоваться Аnalytic или Integration Server.
Объединение всех описанных выше механизмов в Deductor Studio обеспечивает принципиально новое качество анализа: быстрая разработка и адаптация решений, интеграция в существующую инфраструктуру, эволюционное развитие от простой отчетности к глубокой аналитике.
2.3 Работа в аналитической платформе
3.1 Начало работы в аналитической платформе
Запустите Deductor в меню компьютера Пуск. После запуска главное окно Deductor Studio выглядит следующим образом. По умолчанию панель управления представлена одной вкладкой — Сценарии. Кроме того, доступны еще две вкладки: Отчеты и Подключения. Сделать их видимыми можно следующими способами:
главное меню Вид → Отчеты и Вид → Подключения — кнопки Отчетов и Подключений на панели инструментов.
Можно производить «drag & drop» манипуляции с вкладками, меняя их расположение и порядок.
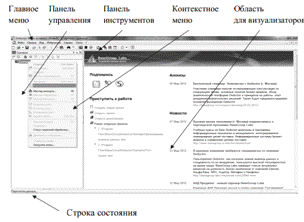
Рис. 3. Рабочая площадь платформы Deductor в момент старта
При нажатии правой кнопки мыши на любой вкладке появляется контекстное меню (рис. 4).
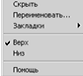
Рис. 4. Контекстное меню вкладки
- Скрыть — делает вкладку невидимой;
- Переименовать — переименовывает название вкладки;
- Закладки — переключается на выбранную закладку;
- Верх/Низ — задает расположение названий вкладок: вверху либо внизу;
- Помощь — открывает раздел справки.
3.2 Понятие проекта
В Deductor Studio ключевым понятием является проект. Это файл с расширением *.ded, по структуре соответствующий стандартному xml-файлу. Он хранит в себе:
- последовательности обработки данных (сценарии);
- настроенные визуализаторы;
- переменные проекта и служебную информацию.
Каждый проект имеет авторские сведения: Название, Версия, Автор, Компания, Описание. Они заполняются в диалоговом окне Свойства проекта (меню Файл→Свойства проекта…).
Создать новый проект можно следующими способами:
- главное меню: Файл→Создать;
кнопка Создать новый проект на панели
клавиша Ctrl+N.
Открытие существующего проекта:
- главное меню: Файл→Открыть;
- кнопка Открыть проект на панели инструментов;
- клавиша Ctrl+O.
Открыть проект можно еще одним способом — в главном меню Файл→История найти имя проекта. Способ работает в том случае, если он сохранился в менеджере историй проектов.
В одной запущенной копии Deductor Studio можно открыть только один проект. В Deductor Studio вся работа ведется с использованием пяти мастеров:
- Мастер импорта;
- Мастер обработки;
- Мастер визуализации;
- Мастер подключений.
С помощью мастеров импорта, экспорта и обработки формируется сценарий. Сценарий состоит из узлов. Мастер подключений предназначен для создания настроек подключений к различным источникам и приемникам данных. Мастер визуализации настраивает визуализаторы для конкретного узла.
Визуализатором называется любое представление набора данных в како-либо виде: табличном, графическом, описательном.
Примеры визуализаторов: таблица, дерево, гистограмма, диаграмма, OLAP-куб.
3.3 Понятие сценария и узла обработки
В Deductor Studio для аналитика основополагающим понятием является сценарий. Сценарий представляет собой последовательность операций с данными, представленную в виде иерархического дерева. В дереве каждая операция образует узел, заголовок которого содержит: имя источника данных, наименование применяемого метода обработки, используемые при этом поля и т. д. Кроме этого, слева от наименования узла стоит значок, соответствующий типу операции (рис. 5).
Если узел имеет подчиненные узлы, то слева от его названия будет расположен значок «+», щелчок по которому позволит развернуть узел, т. е. сделать видимыми все его подчиненные узлы, при этом значок «+» поменяется на «-». Щелчок по значку «-», наоборот, сворачивает все подчиненные узлы.
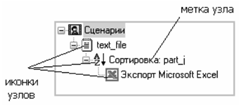
Рис. 5. Сценарная последовательность
С помощью клавиш Ctrl+↑ и Ctrl+↓ можно перемещать узлы по дереву вверх-вниз в пределах подчинения родительскому узлу. Сценарий состоит из ветвей. Deductor не имеет собственных средств для ввода данных, поэтому сценарий всегда начинается с узла импорта из какого-либо источника. Любой вновь создаваемый узел импорта будет находиться на верхнем уровне (подчиненным главному узлу — Сценарии).
Создание нового узла импорта осуществляется с помощью мастера импорта. Вызвать мастер можно следующими способами:
- кнопка Мастер импорта на панели инструментов закладки Сценарии;
- клавиша F6;
- контекстное меню Мастер импорта.
При вызове мастера импорта откроется окно первого шага мастера (рис. 6, а).
В окне могут отражаться все источники данных, сгруппированных по следующим четырем категориям:
- хранилища данных;
- настроенные подключения;
- файлы данных;
- бизнес-подключения.
Однако в нашем случае некоторые категории отсутствуют в списке. Причины этого в следующем:
- версия Deductor. Например, категории Настроенные подключения и Бизнес-подключения отсутствуют в версии Academic;
- в дереве подключений (вкладка Подключения) не зарегистрировано ни одного объекта из данной категории. Например, если не настроено ни одного подключения к хранилищу данных, то категория Хранилища данных будет отсутствовать;
- отключена «видимость» объекта или категории объекта.
Структурированный текстовый файл с разделителями — в нашем случае единственный формат хранения данных. Этот файл представляет собой обычный текстовый файл, столбцы данных в котором разделены однотипными символами-разделителями, например, символами табуляции, пробела, точки с запятой и так далее.
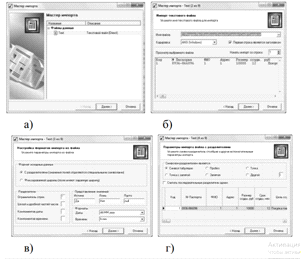
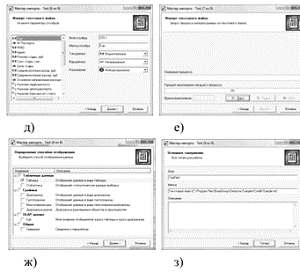
Рис. 6. Мастер импорта
Процесс импорта данных из текстового с разделителями файла в мастере импорта (категория текстовой файл (Direct)) последовательно отображена на рис. 6, б) и содержит следующие шаги:
- указание имени файла;
- настройка параметров импорта;
- настройка импортируемых полей;
- запуск процесса импорта;
- выбор способа визуализации;
- задание сведений об узле.
На шаге Указание имени файла, нажав кнопку, необходимо выбрать имя текстового файла (расширения *.txt, *.csv), из которого следует выполнить импорт данных. После этого в поле «Имя файла» окна Мастера импорта появится имя выбранного файла и путь. Допускается вручную ввести путь к файлу в строке поля «Имя файла». Имеется возможность использовать как абсолютные, так и относительные пути для файлов. Они указываются относительно текущей директории Deductor. При открытии Deductor текущей директорией является директория файла проекта. Поэтому, если файл проекта и текстовые файлы располагаются в одной папке, то использование относительных путей в Мастере импорта позволит не перенастраивать узлы импорта при изменении расположения папки на жестком диске.
Здесь также доступны настройки:
- начать импорт со строки — номер строки, начиная с которой будет делаться импорт данных из файла;
- флаг Первая строка является заголовком — установка флажка означает, что узел будет импортировать данные с учетом того, что все записи первой строки являются заголовками столбцов;
- кодировка — ANSI (Windows) или ANCII (MS DOS).
На шаге Настройка параметров импорта (рис. 6, в, г) нужно настроить параметры импорта данных из текстового файла, так как существует несколько форматов структурированных текстовых файлов. Доступные опции:
- переключатель Формат исходных данных, который определяет символ-разделитель в файле (например, символ табуляции, пробел, запятая).
Разделитель чаще всего присутствует. Если же нет, то нужно выбрать переключатель Фиксированной ширины (поля имеют заданную ширину), а позже установить ширину каждого поля;
- Ограничитель строк — при задании данного параметра необходимо указать, какой именно ограничитель строкового значения нужно использовать при импорте данных из текстового файла. Обычно таким ограничителем является символ двойной кавычки «;
- Разделитель дробной и целой части числа — при задании данного параметра необходимо указать символ, разделяющий дробную и целую части в числовых значениях, содержащихся в файле;
- Разделитель компонентов даты — указывается символ, разделяющий компоненты даты в соответствующих значениях, содержащихся в файле;
- Разделитель компонентов времени — указывается символ, разделяющий компоненты времени в соответствующих значениях, содержащихся в файле;
- Форматы Даты/Времени — указываются форматы даты/времени, используемые в импортируемом файле;
- Представление значений — опция для полей логического типа, которое может принимать одно из трех значений — истина (true), ложь (false) и пустое значение (null).
Дальнейшие шаги мастера импорта будут зависеть от того, какой объект дерева категорий был выбран аналитиком (рис. 6, д).
Выполняя рекомендации в открытом окне, последовательно выбираем требуемый для анализа файл в текстовом формате. Затем выбираем требуемый формат данных и переходим к заданию разделителей, назначая их из перечня. В качестве разделителей, представлений значений и форматов по умолчанию всегда предлагаются системные настройки операционной системы. Поэтому при импорте необходимо обращать внимание на их соответствие формату в импортируемом текстовом файле. Следующее окно мастера зависит от установленного переключателя в флажке Формат исходных данных. Если был выбран формат с разделителями, то появится вкладка, на которой нужно явно указать символ-разделитель (по умолчанию — табуляция).
Здесь же находится флаг Считать последовательные разделители одним — в случае последовательно идущих символов-разделителей они будут восприниматься за один. Такое бывает, например, когда символом-разделителем выступают несколько пробелов. Пред просмотр текстового файла в виде таблицы внизу (загружаются только первые 10 строк) позволяет убедиться в корректности выбора настроек импорта, даже не запуская его. Если был выбран флаг Формат фиксированной ширины, то появится вкладка, на которой нужно задать границы каждого поля. Создание, как и удаление маркера границы, производится одним щелчком мыши. Двигая маркеры границ столбцов, можно изменять их, если они расставлены неправильно. Данные, распределенные по столбцам, показываются в области предварительного просмотра. На шаге Настройка параметров столбцов нужно настроить следующие параметры столбцов, импортируемых данных, указав соответствующие значения в полях.
Имя столбца — указывается имя, которое будет служить идентификатором столбца в последующих узлах. По умолчанию предлагается заголовок столбца из текстового файла, если на предыдущем шаге был установлен флажок Первая строка является заголовком. Иначе будут предложены имена типа COL1, COL2 и т. д. Можно ввести любые имена, которые семантически отражают содержимое столбца, однако допускаются только латинские символы, и имя столбца должно быть уникальным в пределах всех столбцов импортируемого файла.
Метка столбца — название, под которым данный столбец будет виден в визуализаторах. Допускаются любые символы, уникальность имен не обязательна. Тип данных — указывается тип данных, содержащихся в столбце. Тип выбирается из списка, открываемого щелчком по кнопке в правой части поля? Доступные типы данных представлены в таблице 2.
Таблица 2
Типы данных в платформе Deductor
|
Тип Описание |
|
|
Логический дата/время вещественный целый строковый |
данные в поле могут принимать только два значения — 0 или 1 поле содержит данные типа дата/время числа с плавающей точкой целые числа строки символов |
Узел импорта всегда пытается автоматически распознать тип данных по первой строке файла (если имеются заголовки, то по второй строке).
Такой алгоритм срабатывает не всегда.
Непрерывными могут быть только числовые данные. Дискретный характер носят, как правило, строковые данные, но не всегда.
Дискретными могут быть назначены в зависимости от контекста решаемой задачи данные целого типа, реже — вещественного. Вид данных столбца влияет на:
- алгоритм расчета статистики по столбцу;
- работу аналитических алгоритмов.
Назначение — определяет порядок использования поля набора данных, полученного в результате импорта столбца (поля) при дальнейшей обработке импортированных данных, примеры назначений представлены в таблице 3.
Таблица 3.
Назначения полей в платформе Deductor
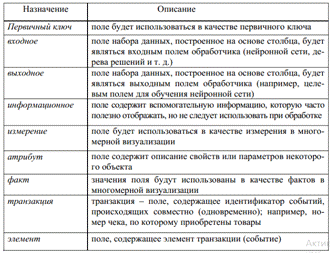
Изменить назначение группы столбцов одной операцией можно следующим образом:
- удерживая клавишу Shift, выделить мышкой или клавишами Ctrl+↓, Ctrl+↑ первый и последний столбцы группы столбцов и изменить их назначение;
- удерживая клавишу Ctrl, выделить мышкой только нужные столбцы и изменить их назначение.
На шаге Запуск процесса импорта стартует сам процесс импорта данных с ранее настроенными параметрами. Ход процесса импорта отображается с помощью индикатора. Если процесс импорта остановился, это сигнализирует о возможных ошибок при чтении данных. В этом случае появляется окно с сообщением об ошибке.
Пуск — запускает процесс в первый раз или возобновляет после паузы;
- Пауза — временно приостанавливает импорт.
Стоп — останавливает процесс без возможности его продолжения.
На оставшихся двух шагах мастера импорта будет предложено выбрать визуализатор набора данных (по умолчанию предлагается Таблица) и задать сведения об узле.
Следующим шагом будет формирование столбцов импортируемого шага, а затем запускаем процесс импорта данных из текстового файла. Последовательно выполняя команду Далее, переходим к способу отображения данных, выбирая из предложенного перечня.
К любому узлу импорта можно добавить узел обработки или узел экспорта, предварительно выделив узел импорта мышью. Новый узел будет добавлен как подчиненный к узлу импорта.

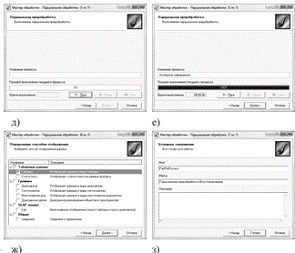
Рис. 7. Мастер обработки
Создание нового узла обработки осуществляется с помощью мастера обработки (Рис. 7).
Вызвать мастер можно следующими способами:
- кнопка Мастер обработки на панели инструментов закладки Сценарии;
- клавиша F7;
- контекстное меню Мастер обработки.
При вызове Мастера обработки откроется окно первого шага мастера.
В нем все обработчики сгруппированы по следующим четырем категориям:
- Очистка данных;
- Трансформация данных;
- Data Mining;
- Прочее.
Некоторые узлы могут отсутствовать в списке. Причины этого следующее:
- версия Deductor;
- отключена «видимость» объекта (или целой категории) объекта;
- узел «устарел» и в текущей версии Deductor его создание невозможно (допускается только его чтение и настройка).
Вызвать Мастер обработки можно следующими способами:
- кнопка Мастер Экспорта на панели инструментов закладки Сценарии;
- клавиша F8;
- контекстное меню Мастер экспорта…
В нем все приемники данных сгруппированы по
хранилища данных;
- базы данных;
- файлы;
- Web-серверы;
- прочее.
Причины отсутствия некоторых объектов или категорий мастера экспорта аналогичны тем, что перечислены при описании мастера импорта. После узла экспорта невозможно добавить ни один узел.
3.4 Базовые операции над узлами сценария
Кроме команд вызова мастеров, к каждому узлу применимы базовые операции. Операции над узлами и ветками сценария можно выполнять следующими способами:
- кнопки панели инструментов на закладке Сценарии;
- контекстное меню;
- мышь.
Список доступных операций.
— Открытие узла — узел запускается на выполнение, причем выполняются все родительские узлы, а справа открываются визуализаторы, настроенные для данного узла. В интерактивном режиме для каждого узла должен быть настроен хотя бы один визуализатор, например, Таблица или Сведения. Операция вызывается:
- двойным щелчком мышью на узле;
- клавишами Ctrl+Enter;
- контекстным меню Открыть.
- Настройка узла — вызывается мастер импорта, мастер обработки или мастер экспорта, в зависимости от типа узла, для изменения параметров обработки, производимой в узле.
Операция вызывается:
- кнопкой;
- клавишами Alt+Enter;
контекстным меню Настроить…
— Активация/деактивация узла — узел может быть либо активным, либо неактивным. Если узел неактивный, то, сделав его активным, выполнится сценарий для этого узла, но визуализаторы отображены не будут. Делая узелне активным, закрываются все визуализаторы для него и для всех подчиненных узлов, а сам узел и подчиненные узлы превращаются в неактивные. Эта операция может быть использована для освобождения памяти. Операция активации/деактивации вызывается:
- клавишами Shift+Enter;
контекстным меню Активный…
- Перечитать данные узла — все узлы до корневого включительно будут закрыты, а затем выполнена ветка сценария от корневого до текущего узла. Операция вызывается контекстным меню Перечитать данные…
- Вырезать узел — удаляет текущий узел из сценария обработки.
Все его потомки при этом перемещаются на один уровень вверх и начинают подчиняться родителю удаленного узла. Операция вызывается:
- кнопкой;
- контекстным меню Вырезать узел.
- Вставить узел — вставляет перед текущим узлом сценария новый узел и вызывает для него мастер обработки. Вставить узел перед узлом импорта данных нельзя. Операция вызывается:
- кнопкой;
- контекстным меню Вставить узел.
После вставки нового узла или удаления существующего узлы потомки могут стать неработоспособными в зависимости от обработки, выполняемой новым узлом.
- Копировать ветвь — копирует ветвь сценария, начиная с текущего узла и включая все его потомки. Операция вызывается:
- кнопкой;
- контекстным меню Копировать ветвь;
- при помощи механизма drag & drop — выделив узел и удерживая нажатой клавишу Ctrl, указать курсором мыши на новый узел, который должен стать родителем старого. При этом переносимая ветка целиком скопируется в новое место.
- Удалить ветвь — удаляет узел сценария и все его под-узлы. Удаленная ветвь восстановлению не подлежит, поэтому к данной операции необходимо подходить с осторожностью. Операция вызывается:
- кнопкой;
- клавишами Ctrl+Del;
- контекстным меню Удалить ветвь.
- Перенос ветви — переносит ветку сценария к новому узлу. Операция производится аналогично копированию ветви с помощью drag & drop без удерживания клавиши Ctrl.
- Переименовать — позволяет изменить метку текущего узла. Операция вызывается:
- клавишей F2;
- Сведения — открывает диалоговое окно Сведения для текущего узла. В нем редактируется имя, метка и описание к узлу. Операция вызывается:
- контекстным меню Сведения…;
открыв скрытую панель узла с помощью кнопки и нажать там одну из кнопок:
Имя, Метка или Описание.
Имя узла может быть задано только латинскими символами, тогда как метка — любыми. Кроме того, имя узла должно быть уникально в пределах одного сценария. Как правило, необходимости в переименовании имен узлов не возникает.
- Статус пакетной обработки — устанавливает статус пакетной обработки для узла.
- Добавить в Избранное — текущий узел добавляется в список избранных узлов.
- Сохранение ветви — вызывается стандартный диалог Сохранение, в котором можно указать путь и имя файла для сохранения ветви сценария, начинающейся с текущего узла. Операция вызывается контекстным меню Сохранить ветвь.
— Загрузка ветви — вызывает стандартный диалог Открытие файла, в котором можно указать путь и имя файла, хранящего ветвь сценария. Загруженная ветвь сценария станет потомком текущего узла. Ветвь, начинающаяся с узла импорта данных, будет добавлена в проект как новая корневая ветвь. Операция вызывается контекстным меню Загрузить ветвь.
По умолчанию ветвь сценария имеет расширение *.deb.
2.3.5 Экспорт в текстовый файл
Выполняется при помощи мастера экспорта. В нем процесс экспорта данных в текстовый файл с разделителями (категория Файлы) содержит следующие шаги:
- настройка форматов экспорта;
- указание символа-разделителя столбцов;
- выбор экспортируемых полей;
- запуск процесса экспорта;
- выбор способа визуализации;
- задание сведений об узле.
На шаге Настройка параметров экспорта задаются параметры экспорта данных из текстового файла аналогично тем, что задавались в мастере импорта. Экспортироваться будут не все поля, а только те, у которых поднят флажок на шаге Выбор экспортируемых полей.
Здесь же задается имя файла экспорта. По умолчанию предлагается имя файла export.txt. Как и в случае с импортом, допускается использовать относительные пути.
4 Создание базы данных и построение диаграмм
Для начала нужно создать свою базу данных. Поскольку Deductor умеет работать с текстовыми файлами как с базами данных, то за основу возьмем именно этот формат файла. Создадим текстовой документ с именем base.txt. Теперь нужно определиться со структурой файла, поскольку он будет являться базой данных, то все его данные должны быть логически разделены по какому-то признаку. Для разделения колонок в базе данных возьмем за основу разделитель «табуляция», а за основу разделения строк в базе данных будет являться «Enter» знак перехода на новую строку. Заполним документ данными, как это выглядит на рисунке 8.
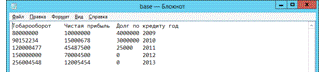
Рис. 8. Содержимое файла base.txt
Откроем программу Deductor Studio Academic как показано на рисунке 9.
Рис. 9. Старт программы Deductor Studio Academic
В левой части экрана есть объект с именем «Сценарий», нажав правой кнопкой мыши по нему всплывет меню объекта как показано на рисунке 10 и выберем пункт «Мастер импорта».
Рис. 10 Меню объекта «Сценарий»
В появившемся мастере импорта (рис. 11) выберем файл данных «Текстовой файл» и жмем кнопку далее.
Рис.11. Мастер импорта
В следующем окне (рис.12) выбираем файл данных base.txt и жмем кнопку «Далее». В окне мастера «3 из 9» (рис. 13) соглашаемся с условиями выбранными разделителями и жмем кнопку далее. В окне мастера «4 из 9» (рис.14) жмем кнопку далее. В окне мастера «5 из 9» свойства всех объектов выставляем как показано на рис. 13. В окне мастера «6 из 9» жмем «Далее». В окне мастера «7 из 9» (рис 15) жмем кнопку «Пуск», а затем «Далее». В окне мастера «8 из 9» (рис. 16) жмем кнопку «Далее», а в «9 из 9» копку «Готово» (рис. 17).
По завершению всех операций в главном окне программы появятся таблицы с импортированными данными (рис. 18).
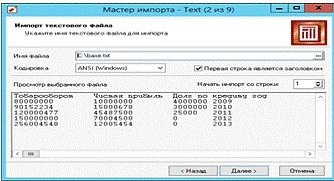
Рис.12. Выбор файла для импорта
Рис. 13. Настройка формата файла для импорта
Рис. 14. Выбор символа — разделителя для импорта
Рис. 15. Настройка параметров столбцов для импорта
Рис. 16. Запуск процесса импорта
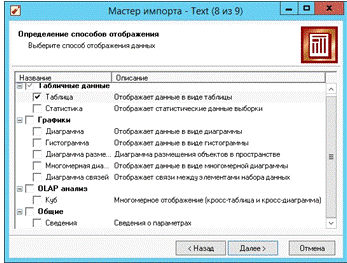
Рис. 17. Определение способов отображения
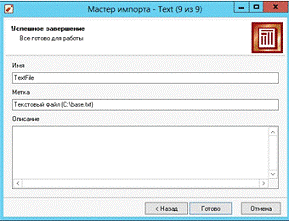
Рис. 18. Завершение импорта файла
Рис. 19. Начало работы с импортированным файлом
Так же можно заметить, что ниже объекта «Сценария» создался еще один объект «Текстовой документ». Пришло время построить отчет в виде диаграмм над анализируемыми данными. Для этого по объекту «Текстовой документ» нужно щелкнуть правой кнопкой мыши и в появившемся меню выбрать пункт «Мастер визуализации» как показано на рис. 20.
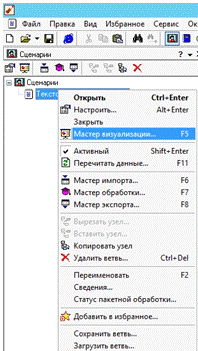
Рис. 20. Мастер визуализации
Откроется окно «Мастер Визуализации» (рис. 20) на котором нужно продолжить работу мастера нажав на кнопку «Далее»
Рис. 21. Мастер визуализации
В следующем окне мастера визуализации «2 из 3» выбираем типы визуализации установкой слева от них галочек, как показано на рис. 22.
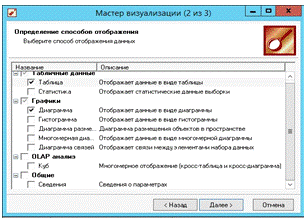
Рис. 22. Мастер визуализации
В следующем окне мастера визуализации настраиваем данные согласно рисунку 23.
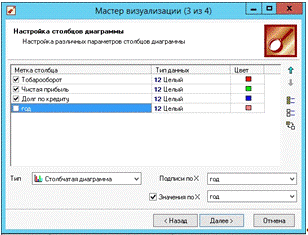
Рис. 23. Мастер визуализации
Далее нам приходится только нажать на кнопку «Готово» для завершения построения визуализации анализируемых данных (рис. 24).
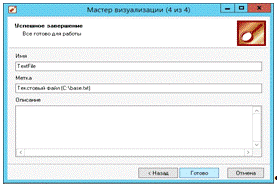
Рис. 24. Мастер визуализации
После этого окно мастера закроется, а на главной области программы появится новая вкладка «Диаграмма», щелкнув по которой левой кнопкой мыши нам откроется созданный отчет с применением визуализации на основе диаграмм, как показано на рис. 25.
Рис. 25
ЗАКЛЮЧЕНИЕ
Практика экономической жизни требует непрерывного обновления знаний и умения добывать их. Обработка накопленных данных, проведение анализа их и построение прогнозов на основе полученной информации являются актуальными проблемами не только финансовых аналитиков, но и практикующих финансовых менеджеров. Наличие специализированных программных средств, позволяющих не просто интерпретировать полученную информацию в виде таблиц и графиков, но и создавать на их базе информационные системы с аналитическими свойствами позволяет значительно формализовать, ускорить и упростить рутинные процессы добывания знаний и принятия решений. Мы закрепили усвоенный теоретический материал практическим заданием и создали самостоятельно базу данных, которую впоследствии визуализировали на основе анализа данных.
Степанов А.Н. Архитектура вычислительных систем и компьютерных сетей : учеб. пособие для студ. вузов / А. Н. Степанов. — М. ; СПб. ; Н. Новгород : Питер, 2007. — 508 с. : рис. — (Учебное пособие).
— Алф. указ.: С. 496-508
Иопа Н.И. Информатика (для технических специальностей) : учеб. пособие / Н. И. Иопа. — М. : Кнорус, 2011. — 470 с. — Библиогр.: С. 470
Провалов В.С. Информационные технологии управления : учеб. пособие / В. С. Провалов ; Рос. акад. образования, Моск. психолого-соц. ин-т. — М. : Флинта, 2008. — 371 с.
Гришин А.Ф. Статистические модели: построение, оценка, анализ : учеб. пособие для студ. вузов / А. Ф. Гришин, Е. В. Кочерова. — М. : Финансы и статистика, 2005. — 416 с.
Голицына О.Л. Базы данных : учеб. пособие / О. Л. Голицина, Н. В. Максимов, И. И. Попов. — М. : Форум — ИНФРА-М, 2006. — 352 с.
Технологии анализа данных: Data Mining, Visual Mining, Text Mining, OLAP : учеб. пособие для вузов / А. А. Барсегян [и др.]. — 2-е изд. перераб. и доп. — СПб. : БХВ-Петербург, 2007. — 375 с.
Лаборатория BaseGroup. Технологии анализа данных. http://www.basegroup.ru