К настоящему времени во многих организациях накоплены значительные объемы данных, на основе которых имеется возможность решения разнообразных аналитических и управленческих задач. Проблемы хранения и обработки аналитической информации становятся все более актуальными и привлекают внимание специалистов и фирм, работающих в области информационных технологий, что привело к формированию полноценного рынка технологий бизнес-анализа.
В идеале работа аналитиков и руководителей различных уровней должна быть организована так, чтобы они могли иметь доступ ко всей интересующей их информации и пользоваться удобными и простыми средствами представления и работы с этой информацией. Именно на достижение этих целей и направлены информационные технологии, объединяющиеся под общим названием хранилищ данных и бизнес-анализа.
1.1 Хранилища данных
1.1.1 Понятие и архитектура системы поддержки принятия решений
В соответствии с определением Gartner, бизнес-анализ (BI, Business Intelligence) — это категория приложений и технологий для сбора, хранения, анализа и публикации данных, позволяющая корпоративным пользователям принимать лучшие решения. В русскоязычной терминологии подобные системы называются также системами поддержки принятия решений.
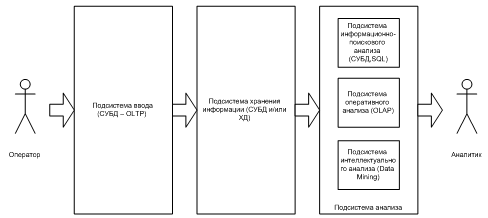
Рисунок 1.1 — Архитектура СППР
Сбор и хранение информации, а также решение задач информационно-поискового запроса эффективно реализуются средствами систем управления базами данных (СУБД).
В OLTP (Online Analytical Processing) — подсистемах реализуется транзакционная обработка данных. Непосредственно OLTP-системы не подходят для полноценного анализа информации в силу противоречивости требований, предъявляемых к OLTP-системам и СППР.
Для предоставления необходимой для принятия решений информации обычно приходится собирать данные из нескольких транзакционных баз данных различной структуры и содержания. Основная проблема при этом состоит в несогласованности и противоречивости этих баз-источников, отсутствии единого логического взгляда на корпоративные данные.
Поэтому для объединения в одной системе OLTP и СППР для реализации подсистемы хранения используются концепция хранилищ данных (ХД).
В основе концепции хранилищ данных лежит идея разделения данных, используемых для оперативной обработки и для решения задач анализа, что позволяет оптимизировать структуры хранения. Хранилище данных позволяет интегрировать ранее разъединенные детализированные данные, содержащиеся в исторических архивах, накапливаемых в традиционных OLTP-системах, поступающих из внешних источников, в единую базу данных, осуществляя их предварительное согласование и, возможно, агрегацию.
Хранилища данных
... хранении и обработке очень больших объемов информации. Реализация хранилищ данных имеет несколько вариантов. 1. Виртуальное хранилище данных. 2. Витрина данных (Data Mart). 3. Глобальное хранилище данных ... OLTP-технологии чаще всего используется фиксированный набор надежных и безопасных методов ввода, модификации, удаления данных ... анализа данных [2]. 2. Системы хранения На хранение корпоративных данных ...
Подсистема анализа может быть построена на основе:
- подсистемы информационно-поискового анализа на базе реляционных СУБД и статических запросов с использованием языка SQL;
- подсистемы оперативного анализа. Для реализации таких подсистем применяется технология оперативной аналитической обработки данных OLAP, использующая концепцию многомерного представления данных;
- подсистемы интеллектуального анализа, реализующие методы и алгоритмы Data Mining.
1.1.2 Понятие хранилища данных
Технология хранилищ данных предназначена для хранения и анализа больших объемов данных с целью дальнейшего обнаружения в них скрытых закономерностей и, наряду с технологией Data Mining, входит в понятие «предсказательная аналитика». Data Mining, в свою очередь, изучает процесс нахождения новых, действительных и потенциально полезных знаний в базах данных. Хранилище данных — предметно-ориентированный, интегрированный, редко меняющийся, поддерживающий хронологию набор данных, организованный для целей поддержки принятия решений. Предметная ориентация означает, что хранилище данных интегрируют информацию, отражающую различные точки зрения на предметную область. Интеграция предполагает, что данные, хранящиеся в что хранилище данных, приводятся к единому формату. Поддержка хронологии означает, что все данные в что хранилище данных соответствуют последовательным интервалам времени. Кроме возможности работать с единым источником информации, руководители и аналитики должны иметь удобные средства визуализации данных, агрегирования, поиска тенденций, прогнозирования. Несмотря на многообразие аналитической деятельности можно выделить типовые технологии анализа данных, каждой из которых соответствует определенный набор инструментальных средств. Вместе с хранилищем данных эти средства обеспечивают полное решение для автоматизации аналитической деятельности и создания корпоративной информационно-аналитической системы.
1.1.3 Физические и виртуальные хранилища данных
При загрузке данных из OLTP-системы в что хранилище данных происходит дублирование данных. Однако в ходе этой загрузки данные фильтруются, поскольку не все из них имеют значение для проведения процедур анализа. В что хранилище данных хранится обобщенная информация, которая в OLTP-системе отсутствует (Рисунок 1.2).
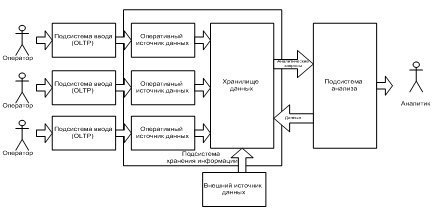
Рисунок 1.2 — Структура СППР с физическим ХД.
Избыточность информации можно свести к нулю, используя виртуальное что хранилище данных. В такой системе данные из OLTP-системы не копируются в единое хранилище. Они извлекаются, преобразуются и интегрируются непосредственно при выполнении аналитических запросов в режиме реального времени. Фактически такие запросы напрямую передаются к OLTP-системе.
Достоинства виртуального хранилище данных:
- минимизация объема хранимых данных;
- работа с текущими, актуальными данными.
Недостатки виртуального что хранилище данных:
Методы сбора данных для анализа социально-экономических и политических процессов
... людьми и т. д. 1.1 Контент-анализ как метод исследования Для сбора географической, экономической, демографической, исторической, культурной информации, данных о политической ситуации не обойтись без анализа различных статистических сведений. Они могут ...
- более высокое, по сравнению с физическим ХД время обработки запросов;
- необходимость постоянной доступности всех OLTP-источников;
- снижение быстродействия OLTP-систем;
— OLTP-системы не ориентированы на хранение данных за длительный период времени, по мере необходимости данные выгружаются в архивные, поэтому не всегда имеется физическая возможность получения полного набора данных в ХД.
1.1.4 Проблематика построения хранилищ данных
Основная проблематика при создании хранилище данных заключается в
- интеграция разнородных данных. Данные в хранилище данных поступают из разнородных OLTP-систем, которые физически могу быть расположены на различных узлах сети. При проектировании и разработке хранилище данных необходимо решать задачу интеграции различных программных платформ хранения;
- эффективное хранение и обработка больших объемов данных.
Построение хранилище данных предполагает накопление данных за значительные периоды времени, что ведет к постоянному росту объемов дисковой памяти, а также росту объема оперативной памяти, требующейся для обработки этих данных. При возрастании объемов данных этот рост нелинеен;
- организация многоуровневых справочников метаданных. Конечным пользователям СППР необходимы метаданные, описывающие структуру хранящихся в хранилище данных данных, а также инструменты их визуализации;
- обеспечение информационной безопасности хранилище данных.
Сводная информация о деятельности компании, как правило, относится к коммерческой тайне и подлежит защите; кроме того, в хранилище данных могут содержаться персональные данные клиентов и сотрудников, которые также необходимо защищать. Для выполнения этой функции должна быть разработана политика безопасности хранилище данных и связанной с ним инфраструктуры, а также реализованы предусмотренные в политике организационные и программно-технические мероприятия по защите информации.
1.1.5 Витрины данных
Сокращение затрат на проектирование и разработку хранилище данных может быть достигнуто путем создания витрин данных (ВД).
Витрины данных — это упрощенный вариант хранилище данных, содержащий только тематически объединенные данные (Рисунок 1.3).
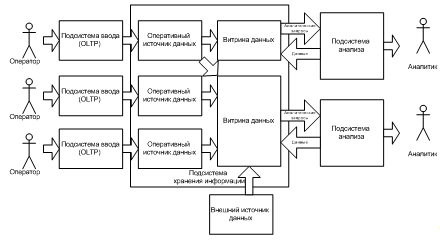
Рисунок 1.3 — Структура СППР с самостоятельными витринами данных
Витрина данных содержит данные, ориентированные на конкретного пользователя, существенно меньше по объему, и для ее реализации требуется меньше затрат. Витрины данных могут строиться как самостоятельно, так и вместе с хранилищем данных. Витрины данных внедряются гораздо быстрее и быстрее виден эффект от их использования. Недостатками витрин данных является многократное хранение одних и тех же данных в различных витринах данных и отсутствие консолидированности на уровне предметной области.
Обычно информация попадает в витрины данных из хранилища данных в этом случае витрины данных называются зависимыми. Возможна также ситуация, когда источником информации для пополнения витрин данных служат непосредственно OLTP-системы. Такие витрины данных, получившие название независимых, как правило, рассматриваются как временное решение, позволяющее достаточно быстро и с небольшими затратами решить наиболее важные задачи, оценить преимущества нового подхода, сформулировать некоторые рекомендации для более масштабного проекта разработки общего хранилища данных. Возможно также совмещение хранилища данных и витрины данных в рамках одной СППР. Хранилища данных в этом случае представляет собой единый источник данных для всей предметной области, а витрины данных являются подмножествами данных из хранилища, организованными для представления информации по тематическим разделам данной области. В том случае, если пользователю, для которого создавалась витрина данных, содержащихся в ней данных недостаточно, то он может обратиться к хранилищу данных (Рисунок 1.4).
Разработка базы данных книжного магазина
... базы данных, которая обеспечит работу с материалами, необходимыми для ведения книжного магазина. База данных «Книжный магазин» содержит: 1. Таблицы; 2. Запросы; 3. Формы; 4. Отчеты; 5. Макросы. Предметной областью своей курсовой работы я выбрала книжный магазин, ... том, что база данных- хранилище информации. В данном курсовом проекте в качестве предметной области рассматривается книжный магазин. Для ...
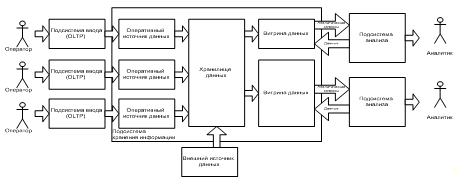
Рисунок 1.4 — Структура СППР с хранилищем данных и витриной данных.
Достоинствами такого решения являются простота создания и наполнения витрины данных, поскольку наполнение происходит из единого стандартизированного источника очищенных данных — из хранилища данных, простота расширения за счет добавления новых витрин данных, а также снижение нагрузки на основное хранилище данных. Недостатки заключаются в избыточности, так как данные хранятся и в хранилище данных, и в витрине данных, а также дополнительные затраты на разработку СППР с хранилищем данных и витриной данных.
1.2 Понятие и модель данных OLAP
1.2.1 Понятие OLAP
OLAP (Online Analytical Processing) — технология оперативной аналитической обработки данных, использующая методы и средства для сбора, хранения и анализа многомерных данных в целях поддержки процессов принятия решений.
1.2.2 Категории данных в хранилище данных
Все данные в хранилище данных делятся на три категории (Рисунок 1.5):
1) детальные данные — данные, переносимые непосредственно из OLTP-подсистем. Соответствуют элементарным событиям, фиксируемым в OLTP-системах. Подразделяются на:
- измерения — наборы данных, необходимые для описания событий (товар, продавец, покупатель, магазин, … );
- факты — данные, отражающие сущность события (количество проданного товара, сумма продаж, …);
2) агрегированные (обобщенные) данные — данные, получаемые на основании детальных путем суммирования по определенным измерениям;
3) метаданные — данные о данных, содержащихся в хранилище данных. Могут описывать:
- объекты предметной области, информация о которых содержится в хранилище данных;
- категории пользователей, использующих данные в хранилище данных;
- места и способы хранения данных;
- действия, выполняемые над данными;
- время выполнения различных действий над данными;
- причины выполнения различных действий над данными.
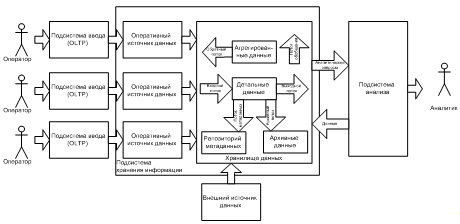
Рисунок 1.5 — Архитектура хранилища данных
1.2.3 Информационные потоки в хранилище данных
Данные в хранилище данных образуют следующие информационные потоки (Рисунок 1.5):
- входной поток — образуется данными, копируемыми из OLTP-систем в хранилище данных;
- данные при этом часто очищаются и обогащаются путем добавления новых атрибутов;
- поток обобщения — образуется агрегированием детальных данных и их сохранением в хранилище данных;
- архивный поток — образуется перемещением детальных данных, количество обращений к которым снизилось;
- поток метаданных — образуется потоком информации о данных в репозиторий данных;
- выходной поток — образуется данными, извлекаемыми пользователями;
- обратный поток — образуется очищенными данными, записываемыми обратно в OLTP-системы.
1.2.4 Структура OLAP-куба
В процессе анализа данных часто возникает необходимость построения зависимостей между различными параметрами, число которых может быть значительным.
Технологии интеллектуального анализа данных
... данных (реализацию интеллектуальных запросов); Выявление устойчивых бизнес - групп (выявление групп объектов, близких по заданным критериям); Ранжирование важности измерений при классификации объектов для проведения анализа; Прогнозирование бизнес - показателей (например, ...
Под измерением будем понимать последовательность значений одного из анализируемых параметров. Например, для параметра «время» это — последовательность дней, месяцев, кварталов, лет.
Возможность анализа зависимостей между различными параметрами предполагает возможность представления данных в виде многомерной модели — гиперкуба (Рисунок 1.6), или OLAP-куба.
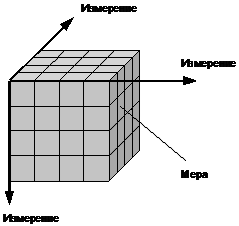
Рисунок 1.6 — Гиперкуб
Оси куба представляют собой измерения, по которым откладывают параметры, относящиеся к анализируемой предметной области, например, названия товаров и названия месяцев года.
На пересечении осей измерений располагаются данные, количественно характеризующие анализируемые факты — меры, например, объемы продаж, выраженные в единицах продукции.
В простейшем случае двумерного куба получается таблица, показывающая значения уровней продаж по товарам и месяцам.
Дальнейшее усложнение модели данных возможно по нескольким направлениям:
- увеличение числа измерений — данные о продажах не только по месяцам и товарам, но и по регионам. В этом случае куб становится трехмерным;
- усложнение содержимого ячейки — например, нас может интересовать не только уровень продаж, но и чистая прибыль или остаток на складе. В этом случае в ячейке будет несколько значений;
- введение иерархии в пределах одного измерения — общее понятие «время» связано с иерархией значений: год состоит из кварталов, квартал из месяцев и т.д.
1.2.5 Иерархия измерений OLAP-кубов
Каждое из измерений OLAP-куба может быть представлено в виде иерархической структуры. Например, измерение «Регион» может иметь следующие уровни иерархии: «страна — федеральный округ — область — город — район». Некоторые измерения могут иметь несколько уровней иерархического представления, например измерение «время» — представление «год — квартал — месяц — день» и представление «год — неделя — день».
Точно так же в рамках измерения «География» можно ввести уровни «Страна», «Регион», «Область» и «Город».
1.2.6 Операции, выполняемые над гиперкубом
Над гиперкубом могут выполняться следующие операции:
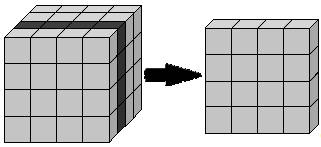
1. Срез (Рисунок 1.7) — формируется подмножество многомерного массива данных, соответствующее единственному значению одного или нескольких элементов измерений, не входящих в это подмножество.
Способы представления статистических данных
... Представление данных таблицы ввиде графика производит более сильное впечатление, чем цифры, позволяет лучше осмыслить результаты статистического наблюдения, правильно их истолковать, значительно облегчает понимание статистического материала, делает его наглядным ... которыми изображены статистические данные. Диаметрические знаки, рисунки или образы, применяемые в статистических графиках, многообразны. ...
Рисунок 1.7 — Срез
2. Вращение (Рисунок 1.8) — изменение расположения измерений, представленных в отчете или на отображаемой странице. Например, операция вращения может заключаться в перестановке местами строк и столбцов таблицы. Кроме того, вращением куба данных является перемещение внетабличных измерений на место измерений, представленных на отображаемой странице, и наоборот.
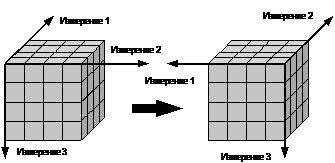
Рисунок 1.8 — Вращение
Консолидация (Рисунок 1.9) и детализация (Рисунок 1.10) — операции, которые определяют переход вверх по направлению от детального представления данных к агрегированному и наоборот, соответственно. Направление детализации (обобщения) может быть задано как по иерархии отдельных измерений, так и согласно прочим отношениям, установленным в рамках измерений или между измерениями.
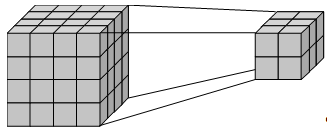
Рисунок 1.9 — Консолидация
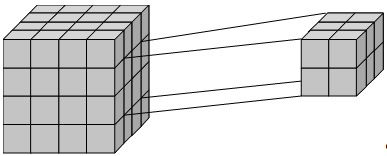
Рисунок 1.10- Детализация
Например, если при анализе данных о продажах в Северной Америке выполнить операцию детализации для измерения «Регион», то будут отображены такие элементы, как «Канада», «Восточные штаты США» и «Западные штаты США». В результате дальнейшей детализации элемента «Канада» будут отображены элементы «Торонто», «Ванкувер» и т.д.
1.2.7 Таблица фактов и измерений
Таблица фактов — является основной таблицей хранилища данных. Как правило, она содержит сведения об объектах или событиях, совокупность которых будет в дальнейшем анализироваться. Обычно говорят о четырех наиболее часто встречающихся типах фактов.
К ним относятся:
- факты, связанные с транзакциями (Transaction facts).
Они основаны на отдельных событиях (типичными примерами которых являются телефонный звонок или снятие денег со счета с помощью банкомата);
- факты, связанные с «моментальными снимками» (Snapshot facts).
Основаны на состоянии объекта (например, банковского счета) в определенные моменты времени, например на конец дня или месяца. Типичными примерами таких фактов являются объем продаж за день или дневная выручка;
- факты, связанные с элементами документа (Line-item facts).
Основаны на том или ином документе (например, счете за товар или услуги) и содержат подробную информацию об элементах этого документа (например, количестве, цене, проценте скидки);
- факты, связанные с событиями или состоянием объекта (Event or state facts).
Представляют возникновение события без подробностей о нем (например, просто факт продажи или факт отсутствия таковой без иных подробностей).
Таблица фактов, как правило, содержит уникальный составной ключ, объединяющий первичные ключи таблиц измерений. Чаще всего это целочисленные значения либо значения типа «дата/время» — ведь таблица фактов может содержать сотни тысяч или даже миллионы записей, и хранить в ней повторяющиеся текстовые описания, как правило, невыгодно — лучше поместить их в меньшие по объему таблицы измерений. При этом как ключевые, так и некоторые неключевые поля должны соответствовать будущим измерениям OLAP-куба. Помимо этого таблица фактов содержит одно или несколько числовых полей, на основании которых в дальнейшем будут получены агрегатные данные.
Для многомерного анализа пригодны таблицы фактов, содержащие как можно более подробные данные (то есть соответствующие членам нижних уровней иерархии соответствующих измерений).
В данном случае предпочтительнее взять за основу факты продажи товаров отдельным заказчикам, а не суммы продаж для разных стран — последние все равно будут вычислены OLAP-средством.
В таблице фактов нет никаких сведений о том, как группировать записи при вычислении агрегатных данных. Например, в ней есть идентификаторы продуктов или клиентов, но отсутствует информация о том, к какой категории относится данный продукт или в каком городе находится данный клиент. Эти сведения, в дальнейшем используемые для построения иерархий в измерениях куба, содержатся в таблицах измерений.
Таблицы измерений содержат неизменяемые либо редко изменяемые данные. В подавляющем большинстве случаев эти данные представляют собой по одной записи для каждого члена нижнего уровня иерархии в измерении. Таблицы измерений также содержат как минимум одно описательное поле (обычно с именем члена измерения) и, как правило, целочисленное ключевое поле (обычно это суррогатный ключ) для однозначной идентификации члена измерения. Если будущее измерение, основанное на данной таблице измерений, содержит иерархию, то таблица измерений также может содержать поля, указывающие на «родителя» данного члена в этой иерархии. Нередко (но не всегда) таблица измерений может содержать и поля, указывающие на «прародителей», и иных «предков» в данной иерархии (это обычно характерно для сбалансированных иерархий), а также дополнительные атрибуты членов измерений, содержавшиеся в исходной оперативной базе данных (например, адреса и телефоны клиентов).
Каждая таблица измерений должна находиться в отношении «один ко многим» с таблицей фактов. Отметим, что скорость роста таблиц измерений должна быть незначительной по сравнению со скоростью роста таблицы фактов; например, добавление новой записи в таблицу измерений, характеризующую товары, производится только при появлении нового товара, не продававшегося ранее.
1.3 OLAP-системы
1.3.1 Архитектура OLAP-систем
Полномасштабная OLAP-система должна выполнять сложные и разнообразные функции, включающие сбор данных из различных источников, их согласование, преобразование и загрузку в хранилище, хранение аналитической информации, регламентную отчетность, поддержку произвольных запросов, многомерный анализ и др.
В настоящее время существуют фактические стандарты построения OLAP-систем, основанных на концепции хранилища данных. Эти стандарты опираются на современные исследования и общемировую практику создания хранилищ данных и аналитических систем.
В общем виде архитектура корпоративной OLAP-системы описывается схемой с тремя выделенными слоями (Рисунок 1.11):
- извлечение, преобразование и загрузка данных;
- хранение данных;
- анализ данных.
Данные поступают из различных внутренних OLTP-систем, от подчиненных структур, от внешних организаций в соответствии с установленным регламентом, формами и макетами отчетности. Вся эта информация проверяется, согласуется, преобразуется и помещается в хранилище и витрины данных. После этого пользователи с помощью специализированных инструментальных средств получают необходимую им информацию для построения различных табличных и графических представлений, прогнозирования, моделирования и выполнения других аналитических задач.
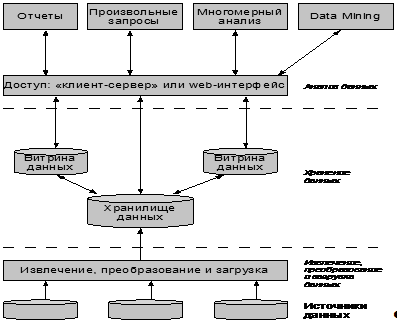
Рисунок 1.11 — Архитектура корпоративной OLAP-системы
Слой извлечения, преобразования и загрузки данных
С организационной точки зрения, данный слой включает подразделения и структуры организации всех уровней, поддерживающие базы данных оперативного доступа. Он представляет собой низовой уровень генерации информации, уровень внутренних и внешних информационных источников, вырабатывающих «сырую» информацию. Эта информация является рабочей для повседневной деятельности различных подразделений, которые ее вырабатывают и используют.
Из источников данных информация перемещается на основе некоторого регламента в централизованное хранилище. Как правило, необходимые для хранилища данные не хранятся в окончательном виде ни в одной из OLTP-систем. Эти данные обычно можно получить из исходных баз данных путем специальных преобразований, вычислений и агрегирования.
Кроме того, несмотря на различную функциональную направленность, исходные транзакционные системы часто «пересекаются» по данным, т.е. их локальные базы данных содержат однотипную по смыслу информацию. Это, прежде всего, касается нормативно-справочной информации, которая используется в том или ином виде в любой OLTP-системе. При этом существенно, что одинаковые по смыслу данные обычно имеют в разных системах различный формат, вид представления, идентификацию, единицы измерения и т.п. Перед загрузкой в хранилище вся эта информация должна быть согласована, чтобы обеспечить целостность и непротиворечивость аналитических данных.
Согласование данных необходимо и при загрузке данных из одного источника. Дело в том, что в хранилище хранятся исторические данные, т.е. данные за достаточно большой промежуток времени. В оперативной системе данные хранятся в целостном виде за ограниченный промежуток, после чего они отправляются в архив. При изменениях в структуре или собственно данных архивы не подвергаются никакой дополнительной обработке, а хранятся в исходном виде. Следовательно, при необходимости иметь данные за достаточно большой период времени необходимо согласовывать архивную информацию с текущей.
Таким образом, загрузка данных из источников в хранилище осуществляется специальными процедурами, позволяющими:
- извлекать данные из различных баз данных, текстовых файлов;
- выполнять различные типы согласования и очистки данных;
- преобразовывать данные при перемещении их от источников к хранилищу;
- загружать согласованные и «очищенные» данные в
Слой хранения данных
Слой хранения данных предназначен непосредственно для хранения значимой, проверенной, согласованной, непротиворечивой и хронологически целостной информации, которую с достаточно высокой степенью уверенности можно считать достоверной.
Собственно хранилище данных не ориентировано на решение какой-либо определенной функциональной аналитической задачи. Цель хранилища данных — обеспечить целостность и поддерживать хронологию всевозможных корпоративных данных, и с этой точки зрения оно нейтрально по отношению к приложениям. В связи с этим в большинстве случаев для выполнения определенного комплекса функционально замкнутых аналитических задач рационально создавать витрины данных, в основе которых может быть как многомерная, так и реляционная модель данных. По существу витрина представляет собой относительно небольшое, но что самое важное, функционально-ориентированное хранилище данных, в котором информация хранится специальным образом, оптимизированным с точки зрения решения конкретных аналитических задач некоторого подразделения или группы аналитиков.
Хранилище данных чаще всего реализуется в виде реляционной БД, работающей под управлением достаточно мощной реляционной СУБД. Такая СУБД должна поддерживать эффективную работу с терабайтными объемами информации, иметь развитые средства ограничения доступа, обеспечивать повышенный уровень надежности и безопасности, соответствовать необходимым требованиям по восстановлению и архивации.
Слой анализа данных
Для организации доступа аналитиков к данным хранилища данных и витринам данных используются специализированные рабочие места, поддерживающие необходимые технологии как оперативного, так и долговременного анализа. Результаты работы аналитиков оформляются в виде отчетов, графиков, рекомендаций и сохраняются как на локальном компьютере, так и в общедоступном узле локальной сети.
Аналитическая деятельность в рамках корпорации достаточно разнообразна и определяется характером решаемых задач, организационными особенностями компании, уровнем и степенью подготовленности аналитиков.
В связи с этим современный подход к инструментальным средствам анализа не ограничивается использованием какой-то одной технологи. В настоящее время принято различать следующие основные вида аналитической деятельности:
- стандартная отчетность;
- нерегламентированные запросы;
- многомерный анализ (OLAP);
- извлечение знаний (data mining).
Каждая из этих технологий имеет свои особенности, определенный набор типовых задач и должна поддерживаться специализированной инструментальной средой.
1.3.2 Клиентские OLAP-средства
Клиентские OLAP-средства представляют собой приложения, осуществляющие вычисление агрегатных данных (сумм, средних величин, максимальных или минимальных значений) и их отображение, при этом сами агрегатные данные содержатся в кэше внутри адресного пространства такого OLAP-средства.
Если исходные данные содержатся в настольной СУБД, вычисление агрегатных данных производится самим OLAP-средством. Если же источник исходных данных — серверная СУБД, многие из клиентских OLAP-средств посылают на сервер SQL-запросы, содержащие оператор GROUP BY, и в результате получают агрегатные данные, вычисленные на сервере.
Как правило, OLAP-функциональность реализована в средствах статистической обработки данных (из продуктов этого класса на российском рынке широко распространены продукты компаний StatSoft и SPSS) и в некоторых электронных таблицах. В частности, средствами многомерного анализа обладает Microsoft Excel. С помощью этого продукта можно создать и сохранить в виде файла небольшой локальный многомерный OLAP-куб и отобразить его двух- или трехмерные сечения.
Надстройки к пакету приложений Microsoft Office для извлечения и обработки данных представляют собой ряд функций, обеспечивающих доступ к возможностям извлечения и обработки данных из приложений Microsoft Office, и тем самым позволяющих осуществлять прогностический анализ на локальном компьютере. Благодаря тому, что встроенные в службы платформы Microsoft SQL Server алгоритмы извлечения и обработки данных доступны из среды приложений Microsoft Office, бизнес-пользователи могут легко извлекать ценную информацию из сложных наборов данных всего несколькими щелчками мыши. Надстройки к пакету приложений Office для извлечения и обработки данных дают конечным пользователям возможность выполнять анализ непосредственно в приложениях Microsoft Excel и Microsoft Visio.
В состав Microsoft Office 2007 входят три отдельных OLAP-компонента:
- клиент извлечения и обработки данных для Excel позволяет создавать проекты извлечения и обработки данных на базе служб SSAS и управлять ими из Excel 2007;
- средства анализа таблиц для приложения Excel позволяют использовать встроенные в службы SSAS функции извлечения и обработки информации для анализа данных, хранящихся в таблицах Excel;
- шаблоны извлечения и обработки данных для приложения Visio позволяют визуализировать деревья решений, деревья регрессии, кластерные диаграммы и сети зависимостей на диаграммах Visio.
С помощью приложения Microsoft Office Visio можно аннотировать, дополнять и отображать графические представления результатов извлечения и обработки данных. Платформа SQL Server 2008 в сочетании с приложением Visio 2007 позволяет:
- визуализировать деревья решений, деревья регрессии, кластерные диаграммы и сети зависимостей;
- сохранять модели извлечения и обработки данных в виде документов Visio, внедренных в другие документы приложений Office или сохраненных в виде веб-страниц.
Клиентские OLAP-средства применяются, как правило, при малом числе измерений (обычно рекомендуется не более шести) и небольшом разнообразии значений этих параметров, — ведь полученные агрегатные данные должны умещаться в адресном пространстве подобного средства, а их количество растет экспоненциально при увеличении числа измерений. Поэтому даже самые примитивные клиентские OLAP-средства, как правило, позволяют произвести предварительный подсчет объема требуемой оперативной памяти для создания в ней многомерного куба.
1.3.3 Серверные OLAP-средства
Преимущества применения серверных OLAP-средств по сравнению с клиентскими OLAP-средствами сходны с преимуществами применения серверных СУБД по сравнению с настольными: в случае применения серверных средств вычисление и хранение агрегатных данных происходят на сервере, а клиентское приложение получает лишь результаты запросов к ним, что позволяет в общем случае снизить сетевой трафик, время выполнения запросов и требования к ресурсам, потребляемым клиентским приложением. Отметим, что средства анализа и обработки данных масштаба предприятия, как правило, базируются именно на серверных OLAP-средствах, например, таких как Oracle Database Server и Microsoft SQL Server.
Некоторые клиентские OLAP-средства (в частности, Microsoft Excel) позволяют обращаться к серверным OLAP-хранилищам, выступая в этом случае в роли клиентских приложений, выполняющих подобные запросы. Помимо этого имеется немало продуктов, представляющих собой клиентские приложения к OLAP-средствам различных производителей.
Oracle Business Intellegence
У компании Oracle существует несколько линеек продуктов класса Business Intelligence. Основная и самая большая называется Oracle Business Intelligence Enterprise Edition PLUS. Business Intelligence (BI) — это самый обширный комплекс технологий и приложений для обеспечения представления внутренней организации бизнеса, включающий ведущие BI-приложения, технологические BI-платформы и хранилища данных.
В BI-платформы Orecle основе лежит аналитический сервер Oracle BI Server EE.
Этот сервер хранит:
описание различных источников данных. В качестве источников данных могут быть практически любые СУБД, как реляционные (Oracle, Microsoft SQL Server, Microsoft Analysis Services, IBM DB2), так и многомерные (MS AS, Hyperion Essbase или SAP BW), а также ODBC источники, текстовые файлы и т.д.
в репозитории хранится бизнес-модель данных, построенная над физическими источниками данных. Бизнес-модель описывает данные в терминах, используемых при проектировании и построении хранилищ данных. Там же описывается, каким образом данные из физических источников соответствуют бизнес-модели.
презентационный слой, представляющий собой витрины данных. В презентационном слое описывается, по сути, как, в каких терминах и в каком наборе будут видны данные разным типам пользователей.Server фактически представляет собой сервер приложений, который по запросу от пользователя вычисляет, какие данные нужны, в каком физическом источнике они находятся и делает запрос к соответствующему источнику или источникам (один запрос может возвращать данные из нескольких разных источников одновременно), после чего, сервер собирает, при необходимости агрегирует или производит дополнительные вычисления и возвращает результат.
С другой стороны, BI Server сам виден в сети как ODBC источник и позволяет делать к себе запросы с помощью любого инструмента или программы, работающей с ODBC. При этом этот сервер остается виртуальным, так как данные на нем не хранятся, а собираются в момент запроса. Аналитический сервер позволяет использовать хранилище как источник данных, одновременно с OLTP системами.
В качестве среды хранения информации в реляционных хранилищ данных и витрин данных используется сервер Oracle Database. Центральным инструментальным средством создания хранилищ и витрин является Oracle Warehouse Builder, построенный на базе современной архитектуры Common Warehouse Metadata. Он предназначен для описания структуры хранилищ данных и витрин данных, проектирования и создания процедур извлечения, согласования и загрузки данных, а также генерации метаданных для средств доступа, например таких, как Discoverer.
Проектировать хранилище можно и с помощью стандартного инструмента Oracle Designer, а затем автоматически перенести описание проекта в репозиторий метаданных Oracle Warehouse Builder.
Microsoft SQL Server Analysis Services
Другой значимой OLAP-технологией является BI-решение от компании Microsoft, построенное на платформе SQL Server и включающее компоненты Analysis Services и Integration Services.
Microsoft SQL Server Analysis Services (SSAS) является базовой платформой для развития систем бизнес-анализа (Business Intelligence).
SSAS 2008 обеспечивают высокую производительность работы приложений и масштабируемость на уровне миллионов записей и тысяч пользователей.
BI-решение компании Microsoft основывается на масштабируемой платформе, предназначенной для интеграции данных, построения хранилищ данных, анализа накопленных данных и построения отчетов. Ядром BI-решения Microsoft является платформа SQL Server. Входящие в нее компоненты, специфические для BI-решения, приведены в Таблица 1.1 .
Таблица 1.1 — Компоненты BI-решения Microsoft
|
Компонент |
Описание |
|
SQL Server Database Engine |
Масштабируемая, высокопроизводительная СУБД, способная хранить большие объемы данных, образующиеся в результате консолидации данных в единое хранилище для анализа и построения отчетов. |
|
SQL Server Integration Services |
Платформа для выполнения операций извлечения, преобразования и загрузки, которая обеспечивает заполнение ХД и его синхронизацию с данными из различных источников, которые используются бизнес-приложениями организации. |
|
SQL Server Analysis Services |
Обеспечивает возможность построения OLAP-решений, включая возможность расчета ключевых индикаторов производительности (KPI). Применяется также для построения data-mining-решений, которые используют специализированные алгоритмы для выявления трендов и зависимостей в бизнес-данных. |
|
SQL Server Reporting Services |
Инструментарий построения отчетов, предназначенный для создания, публикации и распространения детализированных бизнес-отчетов, как для внутренних, так и для внешних целей. |
SSAS построены на основе Унифицированной Многомерной Модели (Unified Dimensional Model, UDM), появившейся в версии 2005, которая позволяет различным типам клиентских приложений получать доступ к данным как из реляционных, так и из многомерных баз данных без использования отдельных моделей для каждого типа баз данных.
Основой UDM является архитектура измерений на основе атрибутов. Архитектура измерений на основе атрибутов дает возможность группировать свойства (атрибуты), определяющие функционирование бизнеса, в одно измерение и отделить эти свойства от правил навигации по измерению — иерархий.
UDM предоставляет возможность использовать множество источников данных (data sources) для создания многомерной модели.
Модель UDM может быть использована для создания единого представления реляционных и многомерных данных, включающих бизнес-объекты, бизнес-аналитику, вычисления и метрики.
Модель UDM создает промежуточный логический уровень между физической реляционной базой данных, используемой в качестве источника данных, и фирменными структурами куба и измерений, используемыми для обработки пользовательских запросов. Таким образом, модель UDM можно представить себе как ядро системы OLAP. Одним из ключевых преимуществ модели UDM является возможность сочетать гибкость и функциональное богатство традиционной реляционной модели генерации отчетов с мощными аналитическими средствами и превосходной производительностью классической модели системы OLAP. В эту модель включен широкий спектр функций бизнес-аналитики, позволяющих эффективнее осуществлять реляционный и OLAP-анализ, и дающих организациям возможность расширять свои решения с использованием механизма ключевых показателей эффективности KPI, а также сложных функций прогностического анализа.
За счет высокой масштабируемости службы SSAS позволяют работать с терабайтными базами данных, и с тысячами пользователей.
Чтобы обеспечить работу большого количества пользователей, избежать конфликтов при пользовании ресурсами и снизить затраты, имеется возможность горизонтального масштабирования служб SSAS. Горизонтальное масштабирование заключается в наращивании вычислительных мощностей и емкости хранилищ данных с целью хранения и синхронизации нескольких версий данных, но в то же время службы SSAS позволяют организовать общий доступ для чтения информации из одной базы данных служб с нескольких серверов, устраняя необходимость в избыточных ресурсах.
Кубы служб SSAS — это многомерные структуры, обеспечивающие высокоскоростной доступ к большим объемам предварительно объединенных данных, и позволяющие конечным пользователям получать интересующие их бизнес-данные в реальном времени. В службах SSAS хранятся бизнес-данные в формате MOLAP, предоставляющем возможность высокой степени оптимизации и сжатия. Присущая этому формату гибкость дает также возможность частично или полностью хранить данные в реляционной базе данных в режиме реляционного OLAP (ROLAP) или в смешанном режиме, называемом гибридным OLAP (HOLAP).
Режим MOLAP обеспечивает значительно более высокую производительность, чем режимы ROLAP и HOLAP.
SSAS предоставляет уровень абстракции над реляционным источником данных — представление источника данных. Представление источника данных позволяет определять таблицы из реляционной базы для использования в многомерной модели. Кроме того, объект представления источника данных позволяет создавать вычисляемые столбцы и представления над реляционными таблицами.
BI-платформа Microsoft предоставляет возможности интеграции с продуктами семейства Microsoft Office System 2007, в частности:
— Microsoft Office Word 2007, как и Microsoft Office Excel 2007, позволяют просматривать отчеты, генерируемые при помощи Reporting Services;
— Microsoft Office Visio 2007 позволяет визуализировать деревья решений, деревья зависимостей, кластерные диаграммы и другие модели технологии data mining;
— Microsoft Office SharePoint Server позволяет создать единый пользовательский интерфейс для просмотра и управления отчетами, генерируемыми при помощи Reporting Services.
.1 Средство разработки
В качестве средства разработки и развертывания проекта куба данных мною была выбрана среда Business Intelligence Development Studio.
SQL Server Business Intelligence Development Studio (BI Dev Studio) — инструмент, предназначенный для разработки полноценных систем бизнес-анализа на основе Analysis Services, Reporting Services и Integration Services.
olap хранилище программный abitura
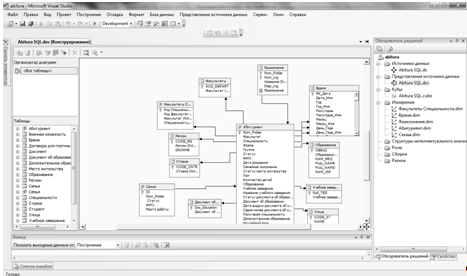
Рисунок 2.1- BI Dev Studio
BI Dev Studio интегрируется в оболочку Visual Studio, что позволяет создавать дополнительные типы проектов для SSAS; При помощи среды BI Dev Studio можно создавать проекты служб SSAS, содержащие определения объектов (кубов, измерений и т.д.) служб SSAS, которые хранятся в XML-файлах, содержащих элементы языка сценариев служб SSAS (ASSL).
Эти проекты содержатся в решениях, где также содержатся проекты из других компонентов SQL Server, включая службы SQL Server Integration Services и SQL Server Reporting Services. В среде BI DevStudio можно разрабатывать проекты служб SSAS как часть решения, которое не зависит от какого-либо конкретного экземпляра служб SSAS. Во время разработки объекты могут быть развернуты на экземпляре на тестовом сервере с целью проверки, после чего этот же проект служб SSAS может быть использован для развертывания объектов в экземплярах на одном или нескольких промежуточных или рабочих серверах. Средой BI DevStudio можно также воспользоваться, чтобы напрямую подсоединиться к существующему экземпляру служб SSAS для создания и изменения объектов служб SSAS, без работы с проектом и без хранения определений объекта в XML-файлах. В BI Dev Studio входит средство оповещения Best Practice Design Alerts, автоматически информирующее о возможных недочетах в проекте на ранних стадиях процесса разработки, и сокращающее потери времени, вызванные проектными ошибками, что существенно ускоряет разработку.
.2 Разработка хранилища данных
В качестве источника данных для хранилища данных была взята база данных Microsoft Access с данными абитуриентов высшего учебного заведения. Данная база данных была развернута на сервере Microsoft SQL Server. По имеющимся данным было спроектировано хранилище данных. Описание полей каждой таблицы базы данных представлено в таблице 2.1.
Таблица 2.1 — Описание таблиц хранилища данных.
|
Таблица |
Название поля |
Описание |
|
Факультет (DEPART) |
Содержит список факультетов. |
|
|
KOD_DEPART (PK) |
Код факультета. Первичный ключ таблицы. |
|
|
Факультет (NAME_DEPAT) |
Содержит название факультета. |
|
|
Образование (KDF_OBR) |
Содержит список доступных образований. |
|
|
OBRAZ (PK) |
Код образования. Первичный ключ таблицы. |
|
|
Образование (FULL_NAMI) |
Имя образования. |
|
|
Страна (KLSTR) |
Содержит список стран. Используется для описания места жительства. |
|
|
CODE_CNTR(PK) |
Код страны. Первичный ключ таблицы. |
|
|
Страна (NAME) |
Название страны. |
|
|
Улица (_STREET) |
Содержит список улиц г. Магнитогорска. |
|
|
CODE_ST (PK) |
Код улицы. Первичный ключ таблицы. |
|
|
SOCR |
Тип ( ул./ пр.) |
|
|
Название |
Полное название улицы. SOCR+’ ‘+NAME |
|
|
Факультеты Специальности. |
Содержит список специальностей. (Именованный запрос) |
|
|
KOD_SPEC (PK) |
Код специальности. Первичный ключ таблицы. |
|
|
KOD_DEPART |
Код факультета. Связан с таблицей DEPART. |
|
|
NAME_DEPAT |
Название факультета. |
|
|
NAME_SPEC |
Название специальности. |
|
|
Семья |
Содержит список родственников абитуриентов. (Именованный запрос) |
|
|
ID (PK) |
ID родственника. Первичный ключ таблицы. |
|
|
Nom_Folder |
ID абитуриента. Связан с таблицей «Абитуриент» |
|
|
ФИО |
Фамилия имя отчество родственника. |
|
|
Место работы |
Место работы родственника. |
|
|
Время |
Таблица, содержащая расшифровку дат. Используется для создания измерения времени. |
|
|
Абитуриент |
Содержит данные абитуриента. (Именованный запрос) |
|
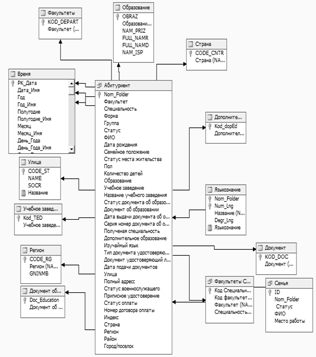
Рисунок 2.2-Схема хранилища данных
Как видно из схемы хранилище состоит из таблиц исходной базы данных связанных между собой и именованных запросов к базе данных.
Таблица «Факультеты Специальности» содержит список всех специальностей сгруппированных по факультетам. Построение таблицы производится на основании двух исходных таблиц (DEPART, SPEC) с данными по факультетам и данными по специальностям. Данная таблица строится на основании следующего именованного запроса:
SELECT [DEPART].[KOD_DEPART]
,[DEPART].[NAME_DEPAT],
[SPEC].NAME_SPEC[abituraSQL1].[dbo].[DEPART],[abituraSQL1].[dbo].[SPEC][DEPART].[KOD_DEPART]=[SPEC].[KOD_DEPART]
Таблица «Семья» содержит список всех родственников абитуриентов с их именами и местом работы. Построение таблицы производится на основании имеющейся таблицы (Family).
Данная таблица строится на основании следующего именованного запроса:
SELECT [Nom_Folder]+ CAST([Nom_pp]as varchar(1)) «ID»
,[Nom_Folder]
,[d_Status]»Статус»
,d_Family+’ ‘+d_Name1+’ ‘+d_Name2 «ФИО»
,Case when d_Work is NULL then ‘ ‘d_Work+’ ‘+when d_Dolgn is NULL then ‘ ‘d_Dolgn»Место работы»[abituraSQL1].[dbo].[Family]
Таблица «Абитуриент» является основной таблицей хранилища данных. Построение данной таблицы производится на основании 5 таблиц (persona, _STREET, Army, F_Address, Договора для платников): Данная таблица строится на основании следующего именованного запроса. Вначале производится построение полей «ФИО», «Дата рождения», «Семейное положение», «Пол», «Количество детей».
SELECT
[persona].[Nom_Folder]
,[persona].Family+’ ‘+[persona].Name1+’ ‘+[persona].Name2 «ФИО»
,[persona].[Date_Bd] «Дата рождения»
, CASE [persona].Fam_Status ‘х’ THEN ‘Холост’
WHEN ‘н’ THEN ‘Не замужем’
WHEN ‘ж’ THEN ‘Женат»з’ THEN ‘Замужем'[persona].Fam_Status»Семейное положение»
,CASE[persona].Foreing_stat=’FALSE’ THEN’Городской’
ELSE ‘Иногородний'»Статус места жительства»
Далее производится построение полей связанных с местом жительства абитуриента. Данные поля строятся на основании данных из таблицы «persona» (для городских жителей) и «F_Address» (для иногородних).
Также производится приведение полей места жительства к единому образцу.
,CASE
WHEN [persona].Foreing_stat=’FALSE’ THEN [persona].[Index_M]
ELSE [F_Address].F_Index»Индекс»
,CASE[persona].Foreing_stat=’FALSE’ THEN ‘643’CASE[F_Address].Kod_Country IS NULL THEN ‘643’[F_Address].Kod_Country»Страна»
,CASE[persona].Foreing_stat=’FALSE’ THEN ’74’CASE[F_Address].F_Region IS NULL THEN ’00′[F_Address].F_Region»Регион»
,CASE[persona].Foreing_stat=’FALSE’ THEN »CASE WHEN [F_Address].F_Raion IS NULL THEN »[F_Address].F_Raion»Район»
,CASE[persona].Foreing_stat=’FALSE’ THEN ‘Магнитогорск’CASE WHEN [F_Address].F_Town IS NULL THEN »[F_Address].F_Town+WHEN [F_Address].F_Point IS NULL THEN »[F_Address].F_Point»Город/поселок»
,CASE[persona].Foreing_stat=’FALSE’ THEN SOCR+’ ‘+NAMECASE WHEN [F_Address].F_Street IS NULL THEN NULL[F_Address].F_Street»Улица»
,CASE[persona].Foreing_stat=’FALSE’ THEN+’ ‘+NAME+’ ‘+CAST(Home_M as Varchar(5))+WHEN Korp_M IS NULL THEN »’/ ‘+Korp_M+WHEN Room_M IS NULL THEN »’ — ‘+Room_M
[F_Address].F_Street+’ ‘+WHEN F_Home IS NULL THEN »’ ‘+F_Home+WHEN F_Korp IS NULL THEN »’/’+F_Korp +WHEN F_Room IS NULL THEN »’ — ‘+F_Room
END «Полный адресс»
Далее следуют поля касающиеся место, формы, место обучения и статуса абитуриента. Данные поля строятся на основании таблицы «persona».
,[Kod_Depat]»Факультет»
,[Kod_Spec]»Специальность»
,[Status]»Форма»
,[Sex]»Пол»
, CASE WHEN Flag_Zach=’FALSE’ THEN’Не принят’CASE WHEN Pref_aGR IS NULL THEN ‘Не определен»Принят'»Статус»
,CASE WHEN Flag_Zach=’FALSE’ THEN NULLCASEPref_aGR IS NULL THEN NULLindex_aGR IS NULL THEN Pref_aGRPref_aGR+’ ‘+index_aGR
END»Группа»
,[Count_Ch]»Количество детей»
,CASE WHEN [Kod_Education] IS NULL THEN ‘007’[Kod_Education]»Образование»
,CASE WHEN [Kod_TED] IS NULL THEN ’00’
ELSE [Kod_TED]»Учебное заведение»
,[Name_ED] «Название учебного заведения»
,CASEDoc_Status =’FALSE’ THEN ‘Подлинник’
ELSE ‘Копия'»Статус документа об образовании»
Также строятся поля касающиеся документов абитуриента: аттестата, паспорта, военного билета. Помимо информации о документах также составляются поля, содержащие информацию о способе оплаты образования. Вся информация по этим полям берётся из таблицы «persona» и «Army».
,[Doc_Education] «Документ об образовании»
,[Date_DE] «Дата выдачи документа об образовании»
,CASE WHEN Nom_De IS NULL THEN »’Номер: ‘+Nom_De+WHEN Ser_DE IS NULL THEN ‘ » Серия: ‘+Ser_DE
END «Серия номер документа об образовании»
,[Spesh_DE] «Полученая специальность»
,CASE WHEN [Add_education] IS NULL THEN ’00’
ELSE [Add_education]»Дополнительное образование»
,[Lng_Education]»Изучаймый язык»
,[Kod_DP] «Тип документа удостоверяющего личность»
,CASE WHEN Ser_DP IS NULL THEN »’Серия: ‘+Ser_DP+WHEN Nom_DP IS NULL THEN »’ #: ‘+Nom_DP+WHEN Date_DP IS NULL THEN »DATENAME(dd, Date_DP) + ‘, ‘
+DATENAME(mm, Date_DP) + ‘ ‘ +DATENAME(yy,Date_DP)+WHEN Who_DP IS NULL THEN »’ Выдан: ‘+Who_DP»Документ удостоверяющий личность»
,CASE WHEN Army_Status=’FALSE’ THEN ‘-‘CASE WHEN Status_AM IS NULL THEN ‘Не годен’Status_AM»Статус военнослужащего»
,CASE WHEN Nom_aDoc IS NULL THEN ‘-»Номер: ‘+Nom_aDoc+WHEN Ser_aDoc IS NULL THEN ‘ » Серия: ‘+Ser_aDoc+WHEN Date_aDoc IS NULL THEN ‘ ‘DATENAME(dd, Date_aDoc) + ‘, ‘
+DATENAME(mm, Date_aDoc) + ‘ ‘
+DATENAME(yy,Date_aDoc)+’ Выдан: ‘+RVK_AM
END «Приписное удостоверение»
,[Data_WR] «Дата подачи документов»
,CASE WHEN Nom_dog IS NUll THEN ‘Бюджет’WHEN Primech_dog IS NUll THEN ‘Не оплачено’
ELSE ‘Частичная оплата'»Статус оплаты»
,’Номер: ‘+Nom_dog+’Дата: ‘
+ DATENAME(dd, Date_Dog) + ‘, ‘
+DATENAME(mm, Date_Dog) + ‘ ‘
+DATENAME(yy,Date_Dog)»Номер договора оплаты»[abituraSQL1].[dbo].[persona]JOIN [abituraSQL1].[dbo].[_STREET] on
[_STREET].[CODE_ST]=[persona].[Street_M] JOIN [abituraSQL1].dbo.[Договора для платников]ON
[persona].[Nom_Folder]=[Договора для платников].nom_folderJOIN [abituraSQL1].dbo.[Army] ON
[F_Address].Nom_Folder=[persona].[Nom_Folder]
2.2.1 Измерения данных
На основании данных получаемых из хранилища данных были созданы следующие измерения:
— Время;
— Специальности _ факультеты;
— Абитуриент;
— Семья;
Измерение «Время» строится на основании таблицы «Время» (см. рисунок 2.3).
Измерения время используется для полей «Дата рождения», «Дата выдачи документа об образовании», «Дата подачи документов» таблицы абитуриент. Данное измерение обладает иерархией изображенной на рисунке 2.3.
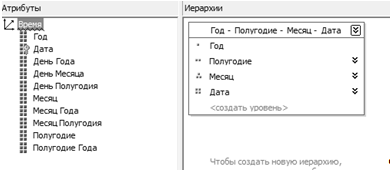
Рисунок 2.3 — Иерархия измерения «Время».
Измерение «Факультеты_Специальности» строится на основании таблицы «Факультеты_Специальности». Измерение «Факультеты_Специальности» используется для классификации абитуриентов по специальностям. Данное измерение обладает собственной иерархией (см. рисунок 2.4).
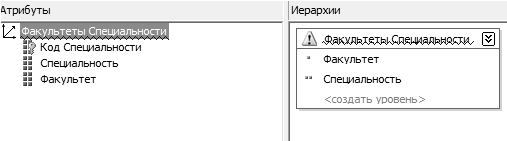
Рисунок 2.4 — Иерархия измерения «Факультеты_Специальности».
Измерение «Семья» строится на основании таблицы «Семья». Данное измерение используется для классификации абитуриентов по родственным связям. Для этого оно обладает собственной иерархией (см. рисунок 2.5).
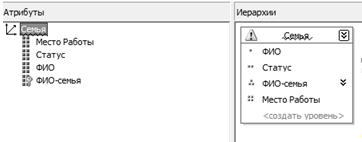
Рисунок 2.5 — Иерархия измерения «Семья».
Измерение «Абитуриент» строится на основании таблицы «Абитуриенты». Данное измерения является основным и производит классификацию и объединение студентов по многим параметрам.
Параметры данного измерения были объединены в 5 групп:
— Абитуриенты (Дата подачи документов, Статус, Статус документа об образовании);
— Личные данные (Дата рождения, Документ удостоверяющий личность, Пол, Приписное удостоверение, Семейное положение, Статус военнослужащего, Тип документа удостоверяющего личность);
— Место жительства (Индекс, Страна, Регион, Район, Улица, Полный адрес, Статус места жительства);
— Образование (Дата выдачи документа об образовании, Дополнительное образование, Изучаемый язык, Название учебного заведения, Название учебного заведения, Образование, Полученная специальность, Серия Номер документ об образовании, Учебное заведение);
— Университет (Группа, Номер договора оплаты, Специальность, Статус оплаты, Факультет, Форма).
Также данное измерение обладает рядом иерархий (см. рисунок 2.6).

Рисунок 2.6 — Иерархия измерения «Абитуриент».
.2.2 Куб данных
На основании выбранных измерений и таблиц хранилища данных был развернут куб данных. В качестве базовых таблиц куба данных были выбраны таблицы «Семья», «Абитуриент». В качестве мер куба данных было выбрана мера «Число» (см. рисунок 2.7).
Данная мера показывает количество абитуриентов данной группы. Были созданы связи между мерами куба и его измерениями (см. рисунок 2.8).
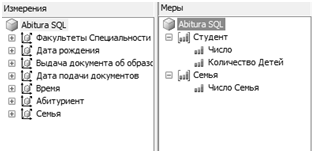
Рисунок 2.7 — Меры и измерения куба.
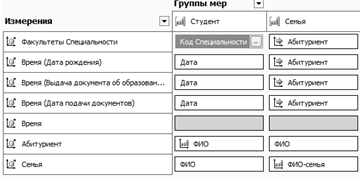
Рисунок 2.8 -Связи мер и измерений куба.
.2.3 Создание Web-отчетов
После развертывания проекта на сервере с кубом данных можно работать по средствам специального браузера (см. рисунок 2.9) Но данный способ требует дополнительного программного обеспеченье. Для решения этой проблемы можно создать web-отчеты, которые будут находиться на SQL сервере, а доступ к ним осуществляется по средствам браузера.
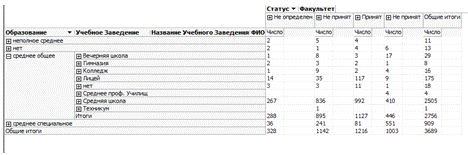
Рис. 2.9 — Работа с кубом данных через браузер.
С использованием SQL Reporting Services были созданы следующие отчеты:
— Год рождения;
— Место жительства;
— Списки зачисления;
— Доп. образование;
— Образование;
— Языкознание;
— Зачисленные;
— Семья.
Для каждого отчета была создана web-форма и написан соответствующий запрос. Запрос для построения формы «Год рождения»:
SELECT NON EMPTY {[Measures].[Число]}
ON COLUMNS,EMPTY {([Дата рождения].[Год].[Год].ALLMEMBERS
*[Абитуриент].[Учебное Заведение].[Учебное заведение].ALLMEMBERS )}
DIMENSION PROPERTIES MEMBER_CAPTION, MEMBER_UNIQUE_NAMEROWS FROM (SELECT ({ [Абитуриент].[Статус].&[Принят]})COLUMNS FROM [Abitura SQL])( [Абитуриент].[Статус].&[Принят] )PROPERTIES VALUE, BACK_COLOR, FORE_COLOR,_VALUE,FORMAT_STRING,FONT_NAME,FONT_SIZE, FONT_FLAGS
Запрос для построения формы «Место жительства»:
SELECT NON EMPTY {[Measures].[Число]}COLUMNS,EMPTY {([Абитуриент].
[Место жительства].[Город_поселок].ALLMEMBERS
* [Абитуриент].[Статус Места Жительства].
[Статус Места Жительства].ALLMEMBERS ) }PROPERTIES MEMBER_CAPTION, MEMBER_UNIQUE_NAMEROWS FROM (SELECT ({[Абитуриент].[Статус].&[Принят]})COLUMNS FROM [Abitura SQL])( [Абитуриент].[Статус].&[Принят] )PROPERTIES VALUE, BACK_COLOR, FORE_COLOR,_VALUE,FORMAT_STRING, FONT_NAME,FONT_SIZE, FONT_FLAGS
Запрос для построения формы «Списки зачисления»:
SELECT NON EMPTY {[Measures].[Число]}COLUMNS, NON EMPTY
{([Абитуриент].[Зачисление].[ФИО].ALLMEMBERS )}PROPERTIES MEMBER_CAPTION, MEMBER_UNIQUE_NAMEROWS FROM (SELECT ({ [Абитуриент].[Статус].&[Принят]})COLUMNS FROM [Abitura SQL])( [Абитуриент].[Статус].&[Принят] )PROPERTIES VALUE, BACK_COLOR, FORE_COLOR,_VALUE,FORMAT_STRING, FONT_NAME,_SIZE, FONT_FLAGS
Запрос для построения формы «Доп. образование»:
SELECT NON EMPTY {[Measures].[Число Семья]}
ON COLUMNS,EMPTY {([Абитуриент].[Дополнительное Образование]
.[Дополнительное Образование].ALLMEMBERS
* [Абитуриент].[Учебное Заведение]
.[Учебное Заведение].ALLMEMBERS )}PROPERTIES MEMBER_CAPTION, MEMBER_UNIQUE_NAMEROWS FROM [Abitura SQL] CELL PROPERTIES, BACK_COLOR, FORE_COLOR, FORMATTED_VALUE,_STRING,FONT_NAME, FONT_SIZE, FONT_FLAGS
Запрос для построения формы «Образование»:
SELECT NON EMPTY {[Measures].[Число] }
ON COLUMNS,EMPTY {([Факультеты Специальности].
[Факультеты Специальности].[Специальность].ALLMEMBERS *
[Абитуриент].[Образование].[Образование].ALLMEMBERS ) }
DIMENSION PROPERTIES MEMBER_CAPTION, MEMBER_UNIQUE_NAMEROWS FROM [Abitura SQL] CELL PROPERTIES, BACK_COLOR, FORE_COLOR, FORMATTED_VALUE, FORMAT_STRING,_NAME, FONT_SIZE, FONT_FLAGS
Запрос для построения формы «Языкознание»:
SELECT NON EMPTY {[Measures].[Число]} COLUMNS,
NON EMPTY{([Абитуриент].[Образование].[Образование].
[Изучаемый Язык].ALLMEMBERS )}
DIMENSION PROPERTIES MEMBER_CAPTION, MEMBER_UNIQUE_NAMEROWS FROM [Abitura SQL] CELL PROPERTIES, BACK_COLOR, FORE_COLOR, FORMATTED_VALUE, FORMAT_STRING,_NAME, FONT_SIZE, FONT_FLAGS
Запрос для построения формы «Зачисленные»:
SELECT NON EMPTY {[Measures].[Число]}COLUMNS,EMPTY{([Абитуриент].[Зачисление].
[Специальность].ALLMEMBERS )}PROPERTIES MEMBER_CAPTION, MEMBER_UNIQUE_NAMEROWS FROM [Abitura SQL] CELL PROPERTIES, BACK_COLOR, FORE_COLOR, FORMATTED_VALUE,_STRING, FONT_NAME, FONT_SIZE, FONT_FLAGS
Запрос для построения формы «Семья»:
SELECT NON EMPTY { [Measures].[Число] }COLUMNS,EMPTY {([Семья].[Семья].[Место Работы].ALLMEMBERS)}PROPERTIES MEMBER_CAPTION, MEMBER_UNIQUE_NAMEROWS FROM [Abitura SQL] CELL PROPERTIES, BACK_COLOR, FORE_COLOR, FORMATTED_VALUE,_STRING, FONT_NAME, FONT_SIZE, FONT_FLAGS
.1 Работа с сервером отчетов Reporting Services
Необходимые отчеты можно получать по средствам Reporting Services. Данное средство позволяет получать отчеты в удобной пользователю web-форме. Для получения отчетов с помощью сервера отчетов необходим web-браузер.
Для начала работы необходимо пройти по адресу сервера отчетов и произвести вход на сервер (ввести логин, пароль).
После пользователь получает список доступных его учетной записи отчетов (см. рисунок 3.1).
После выбора отчета происходит его посторенние, что занимает несколько секунд и вывод в виде html страницы.
Рисунок 3.1 — Окно выбора отчетов.
Существует следующий список отчетов:
— Год рождения (см. рисунок 3.2) — отчет группирует студентов по году рождения и учебному заведению которое они окончили, и выводит их количество;
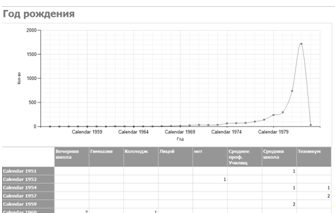
Рисунок 3.2 — Отчет «Год рождения».
— Место жительства (см. рисунок 3.3) — отчет группирует студентов по месту жительства и строит диаграммы;
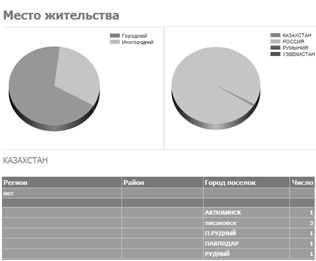
Рисунок 3.3 — Отчет «Место жительства».
— Списки зачисления (см. рисунок 3.4) — отчет формирует списки зачисленных на каждом факультете, специальности;
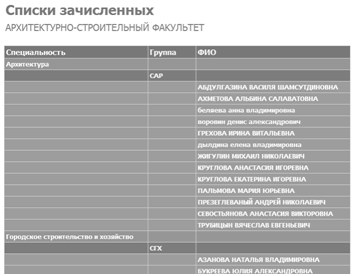
Рисунок 3.4 — Отчет «Списки зачисления».
— Доп. образование (см. рисунок 3.5) — отчет группирует студентов по дополнительным курсам на базе высшего учебного заведения в связи с местом их учебы и выводит их количество;
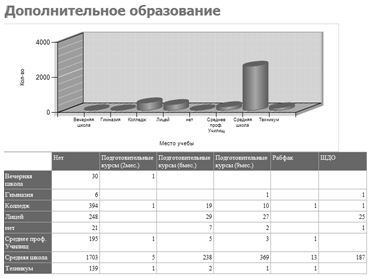
Рисунок. 3.5 — Отчет «Доп. образование».
— Образование (см. рисунок 3.6) — отчет группирует студентов по факультетам и специальностям в связи с их текущим образованием и выводит их количество;
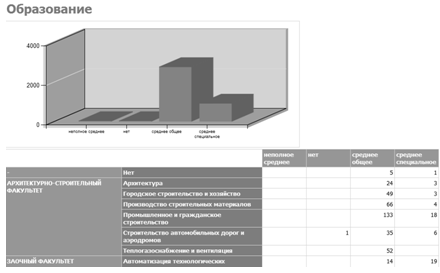
Рисунок. 3.6 — Отчет «Образование».
— Языкознание (см. рисунок 3.7) — отчет группирует студентов изучаемому иностранному языку в связи с их текущим образованием и выводит их количество;
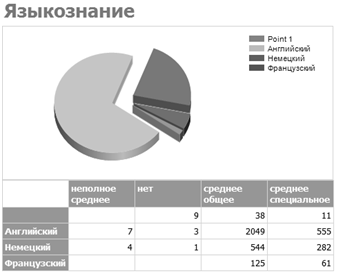
Рисунок. 3.7 — Отчет «Языкознание».
— Зачисленные (см. рисунок 3.8) — отчет выводит информацию о количестве зачисленных и не зачисленных студентов по специальностям;
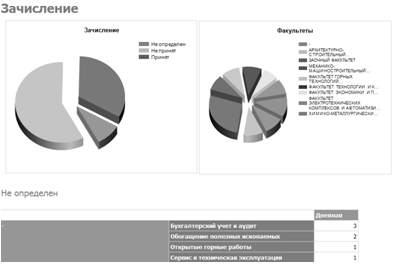
Рисунок 3.8 — Отчет «Зачисленные».
— Семья (см. рисунок 3.9) — отчет группирует родственников по связям с абитуриентом.
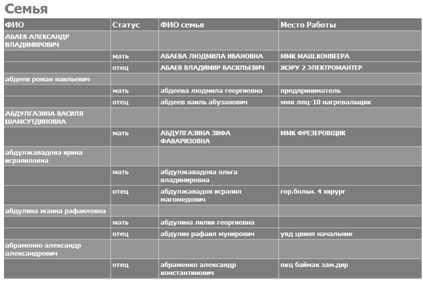
Рисунок 3.9 — Отчет «Семья».
3.2 Работа с кубом данных с использованием Microsoft Office Excel
Работа с отчетами, получаемыми по средствам Reporting Services проста и удобна, но отчеты Reporting Services должны быть спроектированы и развернуты на сервере, поэтому можно работать только с созданными отчетами, что является не всегда удобно. Иногда существует необходимость вывести отчет, который не был предусмотрен.
На этот случай можно воспользоваться Microsoft Office Excel и получить срез куба данных. Для получения отчета Microsoft Office Excel не нужно сложных запросов и с его созданием может справиться обычный пользователь. Вначале необходимо произвести соединение с источником данных (кубом данных).
Необходимо выбрать источник из списка или создать его. При создании источника данных необходимо указать адрес сервера, логин, пароль. Выбрать базу данных и куб данных.
Рисунок 3.10 -Настройка подключения. Выбор сервера.
Рисунок 3.11 -Настройка подключения. Выбор куба данных.
После подключения к кубу данных можно выполнять различные срезы. Для этого необходимо выбрать меры и измерения (см. рисунок 3.12).
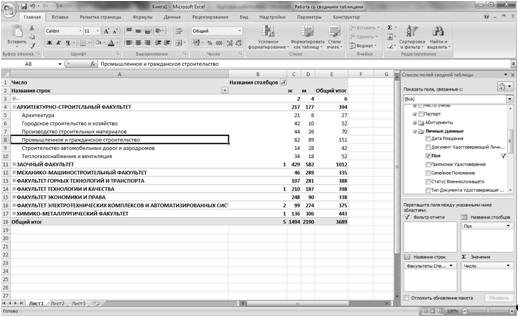
Рисунок 3.12 -Работа с кубом данных в Microsoft Excel.
С использование Microsoft Excel можно сформировать любой срез данных произвести его форматирование. Также можно производить фильтрацию значений по каким-либо выбранным критериям.
В теоретической части были рассмотрены OLAP средства: понятия и классификация витрин и хранилищ данных, понятие куба данных. Также были рассмотрены основные системы для построения OLAP кубов данных и выделены их достоинства и недостатки.
В рамках практической части данной курсовой работы было произведено проектирование и построение хранилища данных. На основании хранилища данных были выбраны измерения данных и меры данных для развертывания куба данных. Для работы с кубом данных были созданы Web-отчеты с использованием технологий Reporting Services. Также была рассмотрена возможность самостоятельного проектирование отчетов с использованием Microsoft Excel.
. Полубояров В.В.- Использование MS SQL Server Analysis Services 2008 для построения хранилищ данных-2008.-487с.
. Сивакумар Харинатх, Стивен Куинн -SQL Server 2005 Analysis Services и MDX для профессионалов.- СПб.: Питер, 2008.-822с.
. Александр Бергер -Microsoft SQL Server 2005 Analysis Services. OLAP и многомерный анализ данных.