Потоковое расширение SIMD (Streaming SIMD Extensions (Single Instruction, Multiple Data — одна команда, несколько элементов данных)) это обобщающее название всех новых возможностей процессоров, начиная с Pentium III, что созданы для повышения производительности в мультимедиа и информационных приложениях. Эти нововведения (включающие новые регистры, типы данных, и команды) объединяются с выполняемой моделью SIMD для повышения быстродействия приложений. Применение новых SIMD-команд значительно увеличивает производительность приложений, обрабатывающих данные с плавающей запятой, или приложений которые в основном используют алгоритмы с интенсивными вычислениями, выполняя повторяющие операции над большими массивами простых данных. Также от SSE выигрывают приложения, которым нужен постоянный доступ к большим размерам данных.
Новые SIMD-команды, реализованные в процессоре Pentium III, увеличивают производительность прикладных программ в следующих областях:
- видео
- комбинирование графики и видео
- обработка изображений
- звуковой синтез
- распознавание, синтез и компрессия речи
- телефония
- видео конференции
- 2D и 3D графика.
В феврале 1999 года Intel представила общественности процессор Pentium III, содержащий обновление технологии MMX, получившей название SSE (Streaming SIMD Extensions — поточные расширения SIMD).
До этого момента инструкции SSE носили имя Katmai New Instructions (KNI), так как первоначально они были включены в процессор Pentium III с кодовым именем Katmai. Процессоры Celeron 533A и выше, созданные на основе ядра Pentium III, тоже поддерживают инструкции SSE. Более ранние версии процессора Pentium II, а также Celeron 533 и ниже (созданные на основе ядра Pentium II) SSE не поддерживают.
Инструкции SSE содержат 70 новых команд для работы с графикой и звуком в дополнение к существующим командам MMX. Фактически этот набор инструкций кроме названия KNI имел еще и второе название — MMX-2. Инструкции SSE позволяют выполнять операции с плавающей запятой, реализуемые в отдельном модуле процессора. В технологиях MMX для этого использовалось стандартное устройство с плавающей запятой.
Инструкции SSE2, содержащие 144 дополнительные команды SIMD, были представлены в ноябре 2000 года вместе с процессором Pentium 4. В SSE2 были включены все инструкции предыдущих наборов MMX и SSE.
Инструкции SSE3 были представлены в феврале 2004 года вместе с процессором Pentium 4 Prescott; они добавляют 13 команд SIMD, предназначенных для ускорения выполнения сложных математических операций, обработки графики, кодирования видео и синхронизации потоков данных. Инструкции SSE3 также содержат все инструкции MMX, SSE и SSE2.
Мультимедиа системы. Компьютер и видео
... правильности сжатия и его величины (скорости потока данных). Видео и анимация. Сейчас, когда сфера применения персональных компьютеров всё ... и иную информацию. Организации и подразделения, обладающие информационными ресурсами и средствами мультимедиа, использующими мультимедийные технологии порой называют медиатеками. Технические средства мультимедиа, как и любые компьютерные информационные системы, ...
В целом SSE обеспечивает следующие преимущества:
- более высокое разрешение/качество при просмотре и обработке графических изображений;
- улучшенное качество воспроизведения звуковых и видеофайлов в формате MPEG2, а также одновременное кодирование и декодирование формата MPEG2 в мультимедийных приложениях;
- уменьшение загрузки процессора и повышение точности/скорости реагирования при выполнении программного обеспечения для распознавания речи.
Инструкции SSE и SSE2 особенно эффективны при декодировании файлов формата MPEG2, который является стандартом сжатия звуковых и видеоданных, используемым в DVD. Следовательно, оснащенные SSE процессоры позволяют достичь максимальной скорости декодирования MPEG2 без использования дополнительных аппаратных средств (например, платы декодера MPEG2).
Кроме того, процессоры, содержащие набор инструкций SSE, значительно превосходят предыдущие версии процессоров при распознавании речи.
Одним из основных преимуществ SSE по отношению к MMX является поддержка операций SIMD с плавающей запятой, что очень важно при обработке трехмерных графических изображений. Технология SIMD, как и MMX, позволяет выполнять сразу несколько операций при получении процессором одной команды. В частности, SSE поддерживает выполнение до четырех операций с плавающей запятой за цикл; одна инструкция может одновременно обрабатывать четыре блока данных. Для выполнения операций с плавающей запятой инструкции SSE могут использоваться вместе с командами MMX без заметного снижения быстродействия. SSE также поддерживает упреждающую выборку данных (prefetching), которая представляет собой механизм предварительного считывания данных из кэш-памяти (L1, L2).
Наилучшие результаты применения новых инструкций процессора обеспечиваются только при их поддержке на уровне используемых приложений. Сегодня большинство компаний, занимающихся разработкой программного обеспечения, модифицировали приложения, связанные с обработкой графики и звука, что позволило в более полной мере использовать возможности SSE. К примеру, графическое приложение Adobe Photoshop поддерживает инструкции SSE, что значительно повышает эффективность использования оснащенных SSE процессоров. Поддержка инструкций SSE встроена в DirectX 6.1 и в самые последние видео и аудио-драйверы, поставляемые с операционными системами Windows 98 Second Edition, Windows Me, Windows NT 4.0 (с пакетом обновления 5 или более поздним), Windows 2000, Windows Vista, Windows 7.
Инструкции SSE являются расширением технологий MMX, а SSE2 — расширением инструкций SSE. Таким образом, процессоры, поддерживающие SSE2, поддерживают также SSE, а процессоры, поддерживающие инструкции SSE, в свою очередь, поддерживают оригинальные команды MMX. Это означает, что стандартные приложения MMX могут выполняться практически на любых системах.
Первые процессоры производства AMD с поддержкой расширений SSE3 —это 0,09-микронные версии Athlon 64, а также все версии двухъядерных процессоров Athlon 64 X2.
Организация данных в компьютере
... В зависимости от порядка точка передвигается (плавает) по мантиссе. Такая форма представления чисел называется формой с плавающей точкой. 1.1 Представление текстовых данных Любой текст состоит из ... компьютера. Существует множество различных форматов представления видеоданных. В среде Windows, применяется формат Video for Windows, базирующийся на универсальных файлах с расширением AVI (Audio Video ...
Общее представление о SSE
SSE обеспечивает инструкции для управления кэшированием всей MMX технологии и 32-битных типов данных. Эти инструкции включают возможность записи данных в память без “засорения” кэша , и возможность упреждающей выборки кода/данных до их использования.
Потоковое Расширение SIMD обеспечивает следующие новые возможности при программировании оборудования IA :
- Восемь SIMD-регистров с плавающей точкой (XMM0 — XMM7).
- Тип данных SIMD (упакованные числа одинарной точности с плавающей точкой) — 128-бит.
- Набор команд SSE.
SIMD-регистры с плавающей точкой
SSEсодержит восемь 128-разрядных регистров общего назначения, каждый из них может быть напрямую адресован. Так как эти регистры новые, то для использования нуждаются в поддержке операционной системы.
SIMD-регистры с плавающей точкой содержат упакованные 128-разрядные данные. Команды SSE обращается к SIMD-регистрам с плавающей точкой используя регистровые имена XMM0 и до XMM7 . SIMD-регистры с плавающей точкой могут быть использованы для вычислений над данными; но не могут быть использованы для адресации памяти. Адресация выполняется с помощью определенных в IA режимов адресации и регистров общего назначения (EAX, EBX, ECX, EDX, EBP, ESI, EDI и ESP).
Также вводится новый регистр контроля/состояния MXCSR, он используется для маскирования и демаскирования обработки числовых исключительных ситуаций, для определения режима округления, для установки режима сброса в ноль, и для просмотра состояния флагов.
Если произошло исчезновение порядка (underflow), а поле flush-to-zero (FZ бит 15) регистра MXCSR установлено в 1, то процессор выполняет следующие действия:
- возвращает нулевое значение в качестве результата, присваивая ему знак истинного результата
- устанавливает в 1 биты 4 и 5 регистра MXCSR (флаги обнаружения исключений исчезновения порядка и неточного результата).
Указанные действия выполняются в том случае, если исключение underflow маскировано (бит 11 регистра MXCSR установлен в 1).
При таком режиме увеличивается скорость работы программ, в которых часто происходит исчезновение порядка результата. Достигается это, однако, ценой снижения точности вычислений.
MMX регистры физически реализованы на стандартных для архитектуры Intel 80-разрядных регистрах данных с плавающей точкой. То есть, переход от операций MMX к операциям с плавающей точкой требует запуска команды EMMS. Но так как SIMD-регистры с плавающей точкой являются отдельным регистровым файлом, то команды MMX и команды с плавающей точкой могут быть смешаны с командами SSE без выполнение специальных инструкций таких как EMMS.
Тип данных SIMD с плавающей точкой
Основной тип данных SSE это 128-разрядное значение, содержащее четыре последовательно расположенных (“упакованных”) 32-разрядных числа одинарной точности с плавающей точкой (single-precision floating-point (SPFP))
Каждое 32-разрядное число с плавающей точкой имеет 1 знаковый бит, 8 битов порядка и 23 бита мантиссы, что соответствует стандарту IEEE-754 на формат представления чисел одинарной точности с плавающей запятой (SPFP‑чисел).
Данный формат сохранен и в процессорах начиная с Pentium III, однако для упакованных чисел с плавающей точкой используется представление в 32-разрядном формате с одинарной точностью. Поэтому в отдельных случаях результаты вычислений с плавающей точкой в архитектуре х87 могут отличаться от результатов таких же вычислений, использующих новые SSE SPFP-команды.
Новые команды SIMD над целыми могут работать над типами данных состоящих из упакованных байт, слов или двойных слов. Новые команды предварительной выборки работают над данными размер которых от 32 байт и выше.
Команды SSE копирует упакованные типы данных (данные одинарной точности с плавающей точкой – двойные слова) в и из памяти в 64-битные или 128-битные блоки. Однако, при вычислении арифметических или логических операций над упакованными данными, SSE работает параллельно над каждым двойным словом заключенным в SIMD регистре с плавающей точкой.
Новые SIMD-команды над целыми подчиняются соглашениям принятых в инструкциях MMX и работают над данными в MMX регистрах, а не в 128-разрядных SIMD регистрах с плавающей точкой.
Модель выполнения SIMD
Так как потоковое расширение SSE поддерживает операции над упакованными типами данных одинарной точности с плавающей точкой, и дополнительные SIMD команды над целыми, поддерживаются операции над упакованными типами данных (байт, слово или двойное слово).
Этот подход был выбран потому что большинство приложений обработки мультимедиа имеют следующие характеристики:
- существенна параллельность;
- широкий динамический уровень, отсюда базированы на переменных с плавающей точкой;
- регулярное и повторяющая выборка шаблонов из памяти;
- локализированные повторяющие операции выполняемые над данными;
- независимый процесс управления данными.
Потоковое Расширение SIMD доступно из всех режимов выполнения: Защищенного режима (Protected mode), реально адресуемого режима (Real-address mode), и виртуального режима 8086 (Virtual 8086 mode).
Формат данных в памяти
В SSE вводиться новый упакованный 128-разрядный тип данных который состоит из четырех чисел одинарной точности с плавающей точкой. Бит 0 это наименьше значащий — бит (LSB), и бит 127 это наибольше значащий — бит (MSB).
Байты в новом формате данных имеют последовательные адреса памяти. Порядок как всегда немного странный, то есть байты с меньшими адресами имеют меньшее значение чем байты с старшими адресами
Формат данных SIMD регистра с плавающей точкой
Значение в SIMD регистрах с плавающей точкой имеет тот же формат, что и 128‑разрядные величины в памяти. Есть два режима доступа к памяти: 128-битный и 32-битный. Таблица 2-1 показывает точность и диапазон типа данных. Кодируется только дробная часть мантиссы. Бит целого будет 1 для всех чисел, за исключением 0 и ненормированного ограниченного числа. Показатель типа данных с обычной точностью кодируется в смещенный формат.
Таблица 2-1. Точность и диапазон SSE типа данных с плавающей точкой
|
Тип Данных |
Длина |
Точность (в битах) |
Приблизительный диапазон нормированного числа | |
| Двоичное | Десятичное | |||
| С одинарной точностью | 32 | 24 | от 2 -126 до 2-127 | от 1.18*10 -38 до 1.70*1038 |
Таблица 2-2 показывает кодирование для всех классов действительных чисел (то есть, ноль, ненормированное ограниченное число, нормированное ограниченное число, и ) и NaN для типа данных с одинарной точностью. Она также показывает формат для вещественных неопределенных значений, то есть QNaN [6] и SNaN[7] которые используются некоторыми функциями SSE для активизации обработчика исключений.
При сохранении вещественных значений в памяти, значения с одинарной точностью сохраняются в памяти в 4 последовательных байтах. 128-битный режим доступа используется для 128-разрядной выборки из памяти, 128-разрядной пересылки между SSE регистрами с плавающей запятой и всеми логическими, распаковки и арифметическими командами. 32-битный режим доступа используется для 32‑разрядной выборки из памяти, 32-разрядной пересылки между SSE регистрами с плавающей запятой и скалярными арифметическими командами.
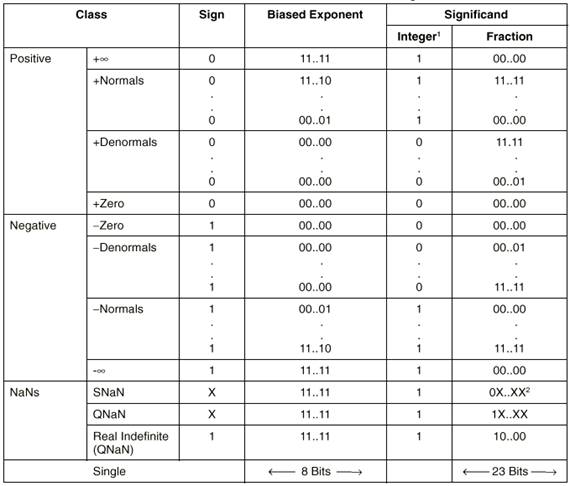
Таблица 2-2. Вещественные числа и кодирование NaN
SIMD регистр состояния и управления
Регистр состояния и управления используется для установки флагов обнаружения арифметических исключений, флагов режимов обработки арифметических исключений, режима округления, режима flush-to-zero и для просмотра флага состояния. Содержимое этого регистра может быть загруженно с помощью инструкций LDMXCSR и FXRSTOR и сохранено в памяти с помощью инструкций STMXCSR и FXSAVE.
Биты 0-5 (поле обнаружения исключений)содержат 6 флагов, которые служат признаками детектирования арифметических SIMD исключений с плавающей точкой (0-нет, 1-да).
Исключение произойдет только после следующей команды SSE. Потоковое расширение SSE использует только один флаг исключения для каждой исключительной ситуации. Здесь не предоставляется возможность для уведомления об индивидуальных исключительных ситуациях внутри упакованных данных. В ситуации, когда происходит несколько идентичных исключительных ситуаций в одной инструкции, соответствующий флаг исключения обновляется и указывает, что хотя бы одно из этих условий произошло. По умолчанию эти флаги сбрасываются.
Биты 7-12 (поле маскирования исключений) определяют, как обрабатываются обнаруженные исключения. Если флаг установлен, то соответствующее исключение маскировано и обрабатывается процессором, который формирует приемлемый результат (в соответствии с процедурой, установленной по умолчанию) и продолжает выполнение программы. Если флаг сброшен, то вызывается программный обработчик для этого исключения. По умолчанию флаги устанавливаются в 1, значит что все исключения маскированы.
Биты 13-14 (RC) устанавливают режим округления результатов при выполнении SSE-команд над данными с плавающей точкой. По умолчанию устанавливается режим округление до ближайшего.
Бит 15 (FZ) используется для включения режима “Flush To Zero”. По умолчанию бит 15 установлен в 0, что выключает режим “Flush To Zero”.
Остальные биты регистра MXCSR (биты 16-31 и бит 6) определены как зарезервированные и установлены в 0; попытка записи не нулевых значений в эти биты, используя инструкцию FXRSTOR или LDMXCSR, вызовет исключение общего нарушения защиты (general protection exception).
Поле управления округлением
Поле управления округлением (RC) регистра MXCSR (биты 13 и 14) управляют как округляется результат инструкции с плавающей точкой.
Поддерживается четыре режима округления:
- округление до ближайшего
- до меньшего или равного
- до большего или равного
- и в сторону нуля (смотреть таблицу 2-3).
Округление до ближайшего — режим по умолчанию и он подходит для большинства приложений. Он обеспечивает наиболее точный и статистически несмещенную оценку правильного результата.
Таблица 2-3. Поле управления округлением (RC)
| Режим округления | Установка полей RC | Описание |
| Округление до ближайшего | 00B | Результатом округления берется наилучшее приближение до точного результата. Если два значения одинаково близки к точному результату, то берется четное значение (то есть, то значение у которого наименьший значащий разряд установлен в ноль) |
| Округление до меньшего или равного (в сторону -) | 01B | Результат округления ближайшее, но не больше чем точное решение. |
| Округление до большего или равного (в сторону +) | 10B | Результат округления ближайшее, но не меньше чем точное решение. |
| Округление в сторону нуля (усечение) | 11B | Результат округления ближайшее, но не больше чем абсолютное значение точного решения. |
Команды Потокового Расширения SIMD
Потоковое Расширение SIMD состоит из 70 команд, сгруппированных в следующие категории:
- Команды копирования данных
- Арифметические команды
- Команды сравнения
- Команды преобразования типов данных
- Логические команды
- Дополнительные целочисленные SIMD-команды
- Команды перестановки
- Команды управления состоянием
- Команды управления кэшированием
Операнды команд
Параллельные операции, как правило, действуют одновременно на все четыре 32-разрядных элемента данных в каждом из 128-разрядных операндов В именах команд, выполняющих параллельные операции, присутствует суффикс ps. Например, команда addps складывает 4 пары элементов данных и записывает полученные 4 суммы в соответствующие элементы первого операнда.
Скалярные операции действуют на младшие (занимающие разряды 0-31) элементы данных двух операндов Остальные три элемента данных в выходном операнде не изменяются (исключение составляет команда скалярного копирования movss).
В имени команд, выполняющих скалярные операции, присутствует суффикс ss (например, команда addss).
Большинство команд имеют два операнда. Данные, содержащиеся в первом операнде, могут использоваться командой, а после ее выполнения, как правило, замещаются результатами. Данные во втором операнде используются в команде и после ее выполнения не изменяются. Далее в тексте входным называется второй операнд, а выходным – первый.
Для всех команд адрес операнда в памяти должен быть выровнен по 16-байтной границе, кроме не выровненных команд сохранения и загрузки.
Пример программы с использованием SSE
Программа выполняет изменение значения цветовых составляющих каждого пикселя картинки (загружаемой с жесткого диска) для применения эффекта размытия.
1. Изображение загружается (посредством диалогового окна) в компоненту «TImage».
2. (после выбора пунктов «операции — Размытие Г.») Проверяется на соответствие формату 24 бита на пиксель.
3. В специальном диалоговом окне, вводится опции (радиус зерна размытия), и запускается обработка изображения.
4. Рассчитывается зерно размытия картинки по установленным параметрам, где производится расчет (списка весов) в несколько этапов.
5. выделяется память для обработки изображения попиксельно, а также для обработки строк.
7. копируется изображение в память ЭВМ.
8. построчно производим эффект гауссово размытия к цветовым составляющим каждого пикселя.
9. теперь каждую колонку с помощью созданного списка весов создаем эффект размытия.
10. обработанные данные записываются в результативный компонент «TImage».
11. освобождается выделенная память для скопированного изображения и обработки строк.
12. (по выбору пункта «операции — сохранить» на вкладке «результат») данные результативного изображения сохраняются в файл.
Листинг программы
const
MaxKernelSize = 64;
- delay_names = ‘миллисекунд’;
//for image
PRGBTriple = ^TPxlC;
TPxlC = record//TPxlC
b:byte;
- g:byte;
- r:byte;
- end;
- PRow = ^TRow; //массив картинки
TRow = array[0..1000000] of TPxlC;
- PPRows = ^TPRows; //массивстрокипикселей
TPRows = array[0..1000000] of PRow;
- TKernelSize = 1..MaxKernelSize;
TKernel = record //зерно
Size: TKernelSize; //размер зерна
Weights: array[-(MaxKernelSize-1)..MaxKernelSize] of single;
- end;
- TXMMSingle = array[0..3] of Single;//массив для SSE
TXMMArrByte = array[0..15] of byte;//массив пикселей
TXMMRsByte = record
item:TXMMArrByte;
- end;
- TSSERegLines = array[0..5] of TXMMRsByte;
//основная процелура размытия
procedure GBlur(theBitmap: TBitmap; radius: double; withSSE:boolean);
var
frm_img: Tfrm_img;
implementation
uses DateUtils, optscopyimg, optsblurimg;
- {$R *.dfm}
const
MAX_imageSize = 65535;
//построение зерна (списка весов) размытия (без SSE)
//MakeGaussianKernel noSSE——————————————————
procedure MakeGaussianKernel(var K: TKernel; radius: double;
- MaxData, DataGranularity: double);
- //Делаем K (гауссово зерно) со среднеквадратичным отклонением = radius.
//Для текущего приложения мы устанавливаем переменные MaxData = 255,
//DataGranularity = 1. Теперь в процедуре установим значение
//K.Size так, что при использовании K мы будем игнорировать Weights (вес)
//с наименее возможными значениями. (Малый размер нам на пользу,
//поскольку время выполнения напрямую зависит от
//значения K.Size.)
var
j: integer;
- temp, delta: double;
- KernelSize: TKernelSize;
- a,b:smallint;
begin
//получили строку весов (зерна)
for j:=Low(K.Weights) to High(K.Weights) do begin
temp := j / radius;
- K.Weights[j] := exp(-(temp * temp) / 2);
- end;
//делаем так, чтобы sum(Weights) = 1:
- temp:=0;
- for j := Low(K.Weights) to High(K.Weights) do
temp := temp + K.Weights[j];//все сумировали
for j := Low(K.Weights) to High(K.Weights) do
K.Weights[j] := K.Weights[j] / temp;//делим каждое на сумму (нормирование)
//теперь отбрасываем (или делаем отметку «игнорировать»
//для переменной Size) данные, имеющие относительно небольшое значение —
//это важно, в противном случае смазавание происходим с малым радиусом и
//той области, которая «захватывается» большим радиусом…
KernelSize := MaxKernelSize;
- delta := DataGranularity / (2 * MaxData);
- temp := 0;
- while (temp <
- delta) and (KernelSize >
- 1) do
begin
temp := temp + 2 * K.Weights[KernelSize];
- dec(KernelSize);
- end;//выравнивание
K.Size := KernelSize;
//теперь для корректности возвращаемого результата проводим ту же
//операцию с K.Size, так, чтобы сумма всех данных была равна единице:
- temp := 0;
- for j := -K.Size to K.Size do
temp := temp + K.Weights[j];//
for j := -K.Size to K.Size do
K.Weights[j] := K.Weights[j] / temp;//
end;
//построение зерна (списка весов) размытия с SSE
//MakeGaussianKernel SSE——————————————————-
procedure MakeGaussianKernelSSE(var K: TKernel; radius: double;
- MaxData, DataGranularity: double);
- //Делаем K (гауссово зерно) со среднеквадратичным отклонением = radius.
//Для текущего приложения мы устанавливаем переменные MaxData = 255,
//DataGranularity = 1. Теперь в процедуре установим значение
//K.Size так, что при использовании K мы будем игнорировать Weights (вес)
//с наименее возможными значениями. (Малый размер нам на пользу,
//поскольку время выполнения напрямую зависит от
//значения K.Size.)
const
nmax=3;
var
j: integer;
- temp, delta: double;
- KernelSize: TKernelSize;
- xmm_n,xmm_r,xmm_a:TXMMSingle;
- _low,_high,na:smallint;
begin
_low:=Low(K.Weights);
- _high:=High(K.Weights);
- j:=_low;
- for na:=0 to nmax do xmm_a[na]:=2;//константа 2
for na:=0 to nmax do xmm_r[na]:=radius;//радиус
asm
push eax
push ebx
push ecx
push edx
movups xmm0,xmm_a//2 в SSE
movups xmm1,xmm_r//радиус в SSE
end;
- while (j<=_high) do begin
for na:=0 to nmax do
if ((j+na)<=_high) then
xmm_n[na]:=j+na
else break;
//копирование простое и передача не дает оптимизации в SSE
asm
movups xmm2,xmm_n //j
divps xmm2,xmm1 //j/radius
movups xmm_n,xmm2
mulps xmm2,xmm2 //temp^2
movups xmm_n,xmm2
divps xmm2,xmm0 //temp*temp/2
movups xmm_n,xmm2
end;//asm
for na:=0 to nmax do begin
if (j<=_high) then
K.Weights[j]:=exp(-xmm_n[na])
else break;
- inc(j);
- end;//for
end;//while
//получили строку весов (зерна)
//делаем так, чтобы sum(Weights) = 1:
- temp:=0;
- for j := Low(K.Weights) to High(K.Weights) do
temp := temp + K.Weights[j];//все сумировали
for j := Low(K.Weights) to High(K.Weights) do
K.Weights[j] := K.Weights[j] / temp;//делим каждое на сумму (нормирование)
for na:=0 to nmax do xmm_n[na]:=temp;
asm
movups xmm0,xmm_n;
- end;
- j:=_low;
- while (j<=_high) do begin
for na:=0 to nmax do begin
if ((j+na)<=_high) then
xmm_n[na]:=K.Weights[j+na]
else break;
- end;//for
asm
movups xmm1,xmm_n
divps xmm1,xmm0//K.Weights[j]/temp
movups xmm_n,xmm1
end;
for na:=0 to nmax do begin
if (j<=_high) then
K.Weights[j]:=xmm_n[na]
else break;
- inc(j);
- end;
- end;//while
//отбрасываем (или делаем отметку «игнорировать»
//для переменной Size) данные, имеющие относительно небольшое значение —
//это важно, в противном случае смазавание происходим с малым радиусом и
//той области, которая «захватывается» большим радиусом…
KernelSize := MaxKernelSize;
- delta := DataGranularity / (2 * MaxData);
- temp := 0;
- while (temp <
- delta) and (KernelSize >
- 1) do
begin
temp := temp + 2 * K.Weights[KernelSize];
- dec(KernelSize);
- end;//выравнивание
K.Size := KernelSize;
//для корректности возвращаемого результата проводим ту же
//операцию с K.Size, так, чтобы сумма всех данных была равна единице:
- temp := 0;
- for j := -K.Size to K.Size do
temp := temp + K.Weights[j];
- for na:=0 to nmax do xmm_n[na]:=temp;
asm
movups xmm0,xmm_n;
- end;
- j:=_low;
- while (j<=_high) do begin
for na:=0 to nmax do begin
if ((j+na)<=_high) then
xmm_n[na]:=K.Weights[j+na]
else break;
- end;//for
asm
movups xmm1,xmm_n
divps xmm1,xmm0//K.Weights[j]/temp
movups xmm_n,xmm1
end;
for na:=0 to nmax do begin
if (j<=_high) then
K.Weights[j]:=xmm_n[na]
else break;
- inc(j);
- end;
- end;//while
asm
pop edx
pop ecx
pop ebx
pop eax
end;
- end;
//TrimInt — округление по указаным границам Integer
function TrimInt(Lower, Upper, theInteger: integer): integer;
begin
if (theInteger <= Upper) and (theInteger >= Lower) then
result := theInteger
else if theInteger > Upper then
result := Upper
else
result := Lower;
- end;
//TrimReal — округление по указанным рамкам Real
function TrimReal(Lower, Upper: integer; x: double): integer;
begin
if (x < upper) and (x >= lower) then
result := trunc(x)
else if x > Upper then
result := Upper
else
result := Lower;
- end;
//BlurRow — размытие строки без SSE
procedure BlurRow(var theRow: array of TPxlC; K: TKernel; P: PRow);
var
j, n: integer;
- tr, tg, tb: double; //tempRed и др.
w: double;
begin
for j := 0 to High(theRow) do
begin
tb := 0;
- tg := 0;
- tr := 0;
- for n := -K.Size to K.Size do
begin
w := K.Weights[n];
- //TrimInt задает отступ от края строки…
with theRow[TrimInt(0, High(theRow), j — n)] do
begin
tb := tb + w * b;
- tg := tg + w * g;
- tr := tr + w * r;
- end;//with
end;//for
with P[j] do
begin
b := TrimReal(0, 255, tb);
- g := TrimReal(0, 255, tg);
- r := TrimReal(0, 255, tr);
- end;
- end;
- Move(P[0], theRow[0], (High(theRow) + 1) * Sizeof(TPxlC));
- end;
//GBlur — полное размытие картинки
procedure GBlur(theBitmap: TBitmap; radius: double; withSSE:boolean);
var
Row, Col: integer;
- theRows: PPRows;
- K: TKernel;
- ACol: PRow;
- P: PRow;
begin
if (theBitmap.HandleType <> bmDIB) or (theBitmap.PixelFormat <> pf24Bit) then
raise
exception.Create(‘GBlur может работать только с 24-битными изображениями’);
if (withSSE) then MakeGaussianKernelSSE(K, radius, 255, 1)
else MakeGaussianKernel(K, radius, 255, 1);
- GetMem(theRows, theBitmap.Height * SizeOf(PRow));
- GetMm(ACol, theBitmap.Height * SizeOf(TPxlC));
- frm_img.img_pbar.Max:=theBitmap.Height+theBitmap.Width+4;
//запись позиции данных изображения:
forRow := 0 totheBitmap.Height — 1 do
theRows[Row] := theBitmap.Scanline[Row];
//размываем каждую строчку:
- P := AllocMem(theBitmap.Width * SizeOf(TPxlC));
- if (frm_imgbluropts.CheckBox1.Checked) then begin
for Row := 0 to theBitmap.Height — 1 do begin
BlurRow(Slice(theRows[Row]^, theBitmap.Width), K, P);
- frm_img.img_pbar.StepBy(1);
- end;
- end;
//теперь размываем каждую колонку
ReAllocMem(P, theBitmap.Height * SizeOf(TPxlC));
- if (frm_imgbluropts.CheckBox2.Checked) then begin
for Col := 0 to theBitmap.Width — 1 do
begin
//- считываем первую колонку в TRow:
- frm_img.img_pbar.StepBy(1);
- for Row := 0 to theBitmap.Height — 1 do
ACol[Row] := theRows[Row][Col];
- BlurRow(Slice(ACol^, theBitmap.Height), K, P);
//теперь помещаем обработанный столбец на свое место в данные изображения:
for Row := 0 to theBitmap.Height — 1 do
theRows[Row][Col] := ACol[Row];
- end;
- end;
- FreeMem(theRows);
- FreeMem(ACol);
- ReAllocMem(P, 0);
- frm_img.img_pbar.Max:=0;
- end;
//end blur———————————————————————
//открыть картинку
procedure Tfrm_img.act_srcOpenImageExecute(Sender: TObject);
begin
if (img_OpenPictureDialog.Execute) then begin
img_src.Picture.LoadFromFile(img_OpenPictureDialog.FileName);
- img_lblImageSizeV.Caption:=format(‘%d — %d’,[img_src.Picture.Width,img_src.Picture.Height]);
- img_log.Lines.Add(format(‘open file «%s»‘,[img_OpenPictureDialog.FileName]));
- img_log.Lines.Add(format(‘image width=»%d» height=»%d»‘,[img_src.Picture.Width,img_src.Picture.Height]));
- end;
- end;
//по высоте картинку — источник
[Электронный ресурс]//URL: https://liarte.ru/referat/tehnologii-obrabotki-multimediynyih-dannyih-sse-sse/
procedure Tfrm_img.act_srcProportionalImgExecute(Sender: TObject);
begin
with (sender as taction) do begin
img_src.Proportional:=Checked;
- end;
- end;
//по высоте картинку — результат
procedure Tfrm_img.act_desProportionalImgExecute(Sender: TObject);
begin
with (sender as taction) do begin
img_des.Proportional:=Checked;
- end;
- end;
//копировать — цветовое копирование картинки с умножением на выбранный цвет
procedure Tfrm_img.act_srcCopyExecute(Sender: TObject);
const
xcount=16;
var
mx,nx,ny,nw,nh:word;
- citm:^TPxlC;
- axmm:TSSERegLines;
- xmm_0:TXMMArrByte;
- nn,xn:byte;
- np1,np2,np3:byte;
- ncolor:tcolor;
- xc:array[0..3] of byte;
- timebefore:Cardinal;
begin
if (frm_optsimgcopy.ShowModal=mrYes) then begin
timebefore:=MilliSecondOfTheHour(Now);
- if (img_src.Picture.Width >
- MAX_imageSize) or (img_src.Picture.Height >
- MAX_imageSize) then begin
MessageDlg(img_errmsg[0].
Text,mtError,[mbok],0);
end else begin
nw:=img_src.Picture.Width;//n size
nh:=img_src.Picture.Height;
- img_des.Picture.Bitmap.Width:=nw;//set n size
img_des.Picture.Bitmap.Height:=nh;
- img_pbar.Max:=nh+1;//set progressbar
ncolor:=frm_optsimgcopy.Shape1.Brush.Color;
- np1:=frm_optsimgcopy.ComboBox1.ItemIndex;
- np2:=frm_optsimgcopy.ComboBox2.ItemIndex;
- np3:=frm_optsimgcopy.ComboBox3.ItemIndex;
for xn:=0 to 4 do begin
xmm_0[xn*3+0]:=GetBValue(ncolor);//blue
xmm_0[xn*3+1]:=GetGValue(ncolor);//green
xmm_0[xn*3+2]:=GetRValue(ncolor);//red
end;
asm
push eax
push ebx
push ecx
push edx
movups xmm1,xmm_0
end;
for ny:=0 to (nh-1) do begin
citm:=img_src.Picture.Bitmap.ScanLine[ny];
- nx:=0;
- while (nx<=nw) do begin
FillChar(xmm_0,16,0);//clear
for nn:=0 to 4 do begin
if ((nx+nn)<=nw) then begin
xmm_0[nn*3+0]:=citm.b;
- xmm_0[nn*3+1]:=citm.g;
- xmm_0[nn*3+2]:=citm.r;
- end else break;//if
inc(citm);
- end;//for
asm//write,make,read
movups xmm0,xmm_0
andps xmm0,xmm1//multiply color’s
movups xmm_0,xmm0
end;//asm
for nn:=0 to 4 do begin
if (nx<=nw) then
img_des.Canvas.Pixels[nx,ny]:=rgb(xmm_0[nn*3+np3],xmm_0[nn*3+np2],xmm_0[nn*3+np1])
else break;
- inc(nx);
- end;//for
end;//while…
img_pbar.StepBy(1);
- end;//for…
asm
pop edx
pop ecx
pop ebx
pop eax
end;
- end;//if…
img_pbar.Max:=0;
- timebefore:=MilliSecondOfTheHour(Now)-timebefore;
- Label1.Caption:=format(‘%d %s’,[timebefore,delay_names]);
- img_log.Lines.Add(format(‘make action=»copy image» at=»%d» milliseconds’,[timebefore]));
- end;
- end;
//инициализация операций
procedure Tfrm_img.FormCreate(Sender: TObject);
begin
img_errmsg[0]:=tstringlist.create;//error msg
img_errmsg[0].
Add(‘Изображение слишком большое.’);//err maxsize image
img_errmsg[0].
Add(format(‘Максимальный размер не должен превышать %d.’,[MAX_imageSize]));
- img_errmsg[0].
Add(‘Попробуйте выбрать другое.’);
- img_tabs.ActivePage:=img_tab1;//page
Label1.Caption:=format(‘0 %s’,[delay_names]);
- end;
//уборка мусора
procedure Tfrm_img.FormDestroy(Sender: TObject);
begin
img_errmsg[0].
Free;
- end;
//Гауссово размытие с применением расширения SSE
procedure Tfrm_img.act_effBlurGauseExecute(Sender: TObject);
var
b: TBitmap;
- fticks:Cardinal;
begin
if (frm_imgbluropts.ShowModal=mrYes) then begin
fticks:=MilliSecondOfTheDay(Now);
- img_des.Picture.LoadFromFile(img_OpenPictureDialog.FileName);
- GBlur(img_des.Picture.Bitmap,frm_imgbluropts.ComboBox1.ItemIndex,True);
- fticks:=MilliSecondOfTheDay(Now)-fticks;
- img_log.lines.add(format(‘make action=»copy blur SSE» at=»%d» milliseconds’,[fticks]));
- Label1.Caption:=format(‘%d %s’,[fticks,delay_names]);
- end;
- end;
//сохранить результат
procedure Tfrm_img.act_desSaveImageExecute(Sender: TObject);
begin
if (img_SavePictureDialog.Execute) then begin
img_des.Picture.SaveToFile(img_SavePictureDialog.FileName);
- end;
- end;
//центрировать результат
procedure Tfrm_img.act_desCenterImgExecute(Sender: TObject);
begin
with (sender as taction) do begin
img_des.Center:=Checked;
- end;
- end;
//растянуть результат
procedure Tfrm_img.act_desStrechImgExecute(Sender: TObject);
begin
with (sender as taction) do begin
img_des.Stretch:=Checked;
- end;
- end;
//центрировать источник
[Электронный ресурс]//URL: https://liarte.ru/referat/tehnologii-obrabotki-multimediynyih-dannyih-sse-sse/
procedure Tfrm_img.act_srcCenterImgExecute(Sender: TObject);
begin
with (sender as taction) do begin
img_src.Center:=Checked;
- end;
- end;
//растянуть источник
[Электронный ресурс]//URL: https://liarte.ru/referat/tehnologii-obrabotki-multimediynyih-dannyih-sse-sse/
procedure Tfrm_img.act_srcStrechImgExecute(Sender: TObject);
begin
with (sender as taction) do begin
img_src.Stretch:=Checked;
- end;
- end;
//Гауссово размытие без SSE (простое)
procedure Tfrm_img.act_effBlurGauseNoSSEExecute(Sender: TObject);
var
b: TBitmap;
- fticks:Cardinal;
begin
if (frm_imgbluropts.ShowModal=mrYes) then begin
fticks:=MilliSecondOfTheDay(Now);
- img_des.Picture.LoadFromFile(img_OpenPictureDialog.FileName);
- GBlur(img_des.Picture.Bitmap,frm_imgbluropts.ComboBox1.ItemIndex,False);
- fticks:=MilliSecondOfTheDay(Now)-fticks;
- img_log.lines.add(format(‘make action=»copy blur» at=»%d» milliseconds’,[fticks]));
- Label1.Caption:=format(‘%d %s’,[fticks,delay_names]);
- end;
- end;
Скриншот программы
Рисунок 3-1 вкладка «источник»
[Электронный ресурс]//URL: https://liarte.ru/referat/tehnologii-obrabotki-multimediynyih-dannyih-sse-sse/
Рисунок 3-2 вкладка «результат»
Вывод
Сравним производительность при использовании оптимизации кода приложения под расширение SIMD процессора SSE и CPU. Тест производился на процессоре Intel® Core™2 DuoCPUT8300 2,4Ghz с поддержкой MMX,SSE-SSE4, EM64T.
Таблица 4-1
| Сравнение времени обработки изображения 800х800 | ||||
| № | время обработки с SSE, мс | время обработки на ЦП, мс | коэфициент ускорения | отклонение от среднего |
| 1 | 840 | 1 032 | 1,2286 | 0,0071 |
| 2 | 841 | 1 047 | 1,2449 | 0,0093 |
| 3 | 832 | 1 033 | 1,2416 | 0,0059 |
| 4 | 839 | 1 028 | 1,2253 | 0,0104 |
| 5 | 836 | 1 035 | 1,2380 | 0,0024 |
Таблица 4-2
| Сравнение времени обработки изображения 1024х768 | ||||
| № | время обработки с SSE, мс | время обработки на ЦП, мс | коэфициент ускорения | отклонение от среднего |
| 1 | 1 589 | 1 940 | 1,2209 | 0,0331 |
| 2 | 1 529 | 1 955 | 1,2786 | 0,0246 |
| 3 | 1 560 | 1 956 | 1,2538 | 0,0002 |
| 4 | 1 551 | 1 954 | 1,2598 | 0,0058 |
| 5 | 1 545 | 1 942 | 1,2570 | 0,0029 |
Таблица 4-3
| Сравнение времени обработки изображения 1600х1200 | ||||
| № | время обработки с SSE, мс | время обработки на ЦП, мс | коэфициент ускорения | отклонение от среднего |
| 1 | 2 369 | 3 037 | 1,2820 | 0,0195 |
| 2 | 2 403 | 3 021 | 1,2572 | 0,0053 |
| 3 | 2 406 | 3 005 | 1,2490 | 0,0135 |
| 4 | 2 389 | 2 989 | 1,2512 | 0,0113 |
| 5 | 2 374 | 3 022 | 1,2730 | 0,0105 |
Таблица 4-4
| Сравнение времени обработки изображения 2560х1600 | ||||
| № | время обработки с SSE, мс | время обработки на ЦП, мс | коэфициент ускорения | отклонение от среднего |
| 1 | 5 054 | 6 332 | 1,2529 | 0,0062 |
| 2 | 5 058 | 6 365 | 1,2584 | 0,0007 |
| 3 | 5 050 | 6 376 | 1,2626 | 0,0035 |
| 4 | 5 024 | 6 321 | 1,2582 | 0,0009 |
| 5 | 4 968 | 6 277 | 1,2635 | 0,0044 |
промежуточный буфер с быстрым доступом
архитектура Intel (Intel architecture )
Указанный режим работы не является согласованным с требованиями стандарта IEEE 754
Определяет формат хранения мантиссы, экспоненты и знака, форматы положительного и отрицательного нуля, плюс и минус бесконечностей, а также определение «не числа» (NaN), методы, обработку ситуаций
Not a Number — не число
Quiet NaN — «тихий NaN»
Signalling NaN — «сигнализирующий NaN»