В настоящее время, в веке информационных технологий, когда потоки информации достигают предела плотности трафика каналов передачи, наряду с задачами обработки информации, возникают наиболее важные задачи ее упорядочивания, хранения и оперативности доступа к ней.
Именно поэтому понимание принципов построения и функционирования, а также грамотное создание и работа с различными структурами хранения данных (файлами, базами данных, файловыми системами), является одним из главных аспектов при подготовке специалистов. Изучение данных вопросов и закрепление практических навыков необходимо для взращивания уверенных пользователей ПК.
Люди имеют дело со многими видами информации. Услышав прогноз погоды, можно записать его в компьютер, чтобы затем воспользоваться им. В компьютер можно поместить фотографию своего друга или видеосъемку о том, как вы провели каникулы. Но ввести в компьютер вкус мороженого или мягкость покрывала никак нельзя.
Компьютер — это электронная машина, которая работает с сигналами. Компьютер может работать только с такой информацией, которую можно превратить в сигналы. Если бы люди умели превращать в сигналы вкус или запах, то компьютер мог бы работать и с такой информацией. У компьютера, очень хорошо, получается, работать с числами. Он может делать с ними все, что угодно. Все числа в компьютере закодированы «двоичным кодом», то есть, представлены с помощью всего двух символов 1 и 0, которые легко представляются сигналами. Вся информация, с которой работает компьютер, кодируется числами. Независимо от того, графическая, текстовая или звуковая эта информация, что бы ее мог обрабатывать центральный процессор она должна тем или иным образом быть представлена числами.
I. Представление данных и команд
Данные — это материальные объекты произвольной формы, выступающие в качестве средства представления информации. Преобразование и обработка данных позволяют извлечь информацию, т. е. данные служат исходным «сырьем» для получения информации. Фиксация информации в виде данных осуществляется с помощью конкретных средств общения на конкретном физическом носителе.
Нормальная форма записи числа имеет следующий вид, где т — мантисса числа; р — порядок; d — основание системы счисления.
Порядок указывает местоположение в числе точки, отделяющей целую часть числа от дробной части. В зависимости от порядка точка передвигается (плавает) по мантиссе. Такая форма представления чисел называется формой с плавающей точкой.
Базы данных и управление ими
... данных. Для обеспечения этих функций созданы специализированные средства – системы управления базами данных (СУБД). Современные СУБД - многопользовательские системы управления базой данных, которые специализируется на управлении массивом информации одним или множеством одновременно работающих ...
1.1 Представление текстовых данных
Любой текст состоит из последовательности символов. Символами могут быть буквы, цифры, знаки препинания, знаки математических действий, круглые и квадратные скобки и т.д. Особо обратим внимание на символ «пробел», который используется для разделения слов и предложений между собой. Хотя на бумаге или экране дисплея «пробел» — это пустое, свободное место, этот символ ничем не «хуже» любого другого символа. На клавиатуре компьютера или пишущей машинки символу «пробел» соответствует специальная клавиша.
Текстовая информация, как и любая другая, хранится в памяти компьютера в двоичном виде. Для этого каждому символу ставится в соответствие некоторое неотрицательное число, называемое кодом символа, и это число записывается в память ЭВМ в двоичном виде. Конкретное соответствие между символами и их кодами называется системой кодировки. В современных ЭВМ, в зависимости от типа операционной системы и конкретных прикладных программ, используются 8-разрядные и 16-разрядные коды символов. Использование 8-разрядных кодов позволяет закодировать 256 различных знаков, этого вполне достаточно для представления многих символов, используемых на практике. При такой кодировке для кода символа достаточно выделить в памяти один байт. Так и делают: каждый символ представляют своим кодом, который записывают в один байт памяти.
1.2 Представление изображений
Все известные форматы представления изображений (как неподвижных, так и движущихся) можно разделить на растровые и векторные.
В векторном формате изображение разделяется на примитивы — прямые линии, многоугольники, окружности и сегменты окружностей, параметрические кривые, залитые определенным цветом или шаблоном, связные области, набранные определенным шрифтом отрывки текста и т. д. Для пересекающихся примитивов задается порядок, в котором один из них перекрывает другой. Некоторые форматы, например, PostScript, позволяют задавать собственные примитивы, аналогично тому, как в языках программирования можно описывать подпрограммы. Такие форматы часто имеют переменные и условные операторы и представляют собой полнофункциональный (хотя и специализированный) язык программирования.
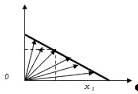
Рис. 1 Двухмерное векторное изображение
Каждый примитив описывается своими геометрическими координатами. Точность описания в разных форматах различна, нередко используются числа с плавающей точкой двойной точности или с фиксированной точкой и точностью до 16-го двоичного знака. Координаты примитивов бывают как двух-, так и трехмерными. Для трехмерных изображений, естественно, набор примитивов расширяется, в него включаются и различные поверхности — сферы, эллипсоиды и их сегменты, параметрические многообразия и др.
Рис. 2 Трехмерное векторное изображение
1.3 Представление звуковой информации
Приёмы и методы работы со звуковой информацией пришли в вычислительную технику наиболее поздно. К тому же, в отличие от числовых, текстовых и графических данных, у звукозаписей не было столь же длительной и проверенной истории кодирования. В итоге методы кодирования звуковой информации двоичным кодом далеки от стандартизации. Множество отдельных компаний разработали свои корпоративные стандарты, но среди них можно выделить два основных направления. Метод FM (Frequency Modulation) основан та том, что теоретически любой сложный звук можно разложить на последовательность простейших гармонических сигналов разных частот, каждый из которых представляет собой правильную синусоиду, а, следовательно, может быть описан числовыми параметрами, т.е. кодом. В природе звуковые сигналы имеют непрерывный спектр, т.е. являются аналоговыми. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальные устройства — аналогово-цифровые преобразователи (АЦП).
Представление информации в ЭВМ
... аналоговой информацией, а вычислительная техника, наоборот, в основном, работает с цифровой информацией. 1. Представление информации в ЭВМ 1.1 Непрерывная и дискретная информация Человек воспринимает информацию с ... важна с точки зрения информатики. Компьютер – цифровая машина, т.е. внутреннее представление информации в нем дискретно. Дискретизация входной информации (если она непрерывна) позволяет ...
Рис. 3 Звуковая информация
Существуют два способа звукозаписи:
- цифровая запись, когда реальные звуковые волны преобразуются в цифровую информацию путем измерения звука тысячи раз в секунду;
- MIDI-запись, которая, вообще говоря, является не реальным звуком, а записью определенных команд-указаний (какие клавиши надо нажимать, например, на синтезаторе).
MIDI-запись является электронным эквивалентом записи игры на фортепиано.
Для того чтобы воспользоваться первым указанным способом в компьютере должна быть звуковая карта (плата).
Реальные звуковые волны имеют весьма сложную форму и для получения их высококачественного цифрового представления требуется высокая частота квантования. Звуковая плата преобразует звук в цифровую информацию путем измерения характеристики звука (уровень сигнала) несколько тысяч раз в секунду. То есть аналоговый (непрерывный) сигнал измеряется в тысячах точек, и получившиеся значения записываются в виде 0 и 1 в память компьютера.
1.4 Представление видео
В последнее время компьютер все чаще используется для работы с видеоинформацией. Простейшей, с позволения сказать, работой является просмотр кинофильмов и видеоклипов, а также многочисленные видеоигры. Более правомерно данным термином называть создание и редактирование такой информации с помощью компьютера.
Существует множество различных форматов представления видеоданных. В среде Windows, применяется формат Video for Windows, базирующийся на универсальных файлах с расширением AVI (Audio Video Interleave — чередование аудио и видео).
Суть AVI файлов состоит в хранении структур произвольных мультимедийных данных, каждая из которых имеет простой вид, изображенный. Файл как таковой представляет собой единый блок, причем в него, как и в любой другой, могут быть вложены новые блоки. Заметим, что идентификатор блока определяет тип информации, которая хранится в блоке. Внутри описанного выше своеобразного контейнера информации (блока) могут храниться абсолютно произвольные данные, в том числе, например, блоки, сжатые разными методами. Таким образом, все AVI-файлы только внешне выглядят одинаково, а внутри могут различаться очень существенно. Еще более универсальным является мультимедийный формат Quick Time, первоначально возникший на компьютерах Apple. По сравнению с описанным выше, он позволяет хранить независимые фрагменты данных, причем даже не имеющие общей временной синхронизации, как этого требует AVI. В результате в одном файле может, например, храниться песня, текст с ее словами, нотная запись в MIDI-формате, способная управлять синтезатором, и т.п. Мощной особенностью Quick Time является возможность формировать изображение на новой дорожке путем ссылок на кадры, имеющиеся на других дорожках. Полученная таким способом дорожка оказывается несоизмеримо меньше, чем, если бы на нее были скопированы требуемые кадры. Благодаря описанной возможности файл подобного типа легко может содержать не только полную высококачественную версию видеофильма, но и специальным образом «упрощенную» копию для медленных компьютеров, а также рекламный ролик, представляющий собой «выжимку» из полной версии.
1.5 Представление команд
Команда представляет собой код, содержащий информацию, необходимую для управления машинной операцией. Под операцией понимают преобразование информации, выполняемое машиной под воздействием одной команды. Содержанием машинной операции может быть запоминание, передача, арифметическое и логическое преобразование некоторых машинных слов (операндов).
По характеру выполняемых операций различают следующие основные группы команд:
- команды арифметических операций для чисел с фиксированной и плавающей запятой;
- команды десятичной арифметики;
- команды логических (поразрядных) операций (И, ИЛИ и др.);
- команды пересылки;
- команды операций ввода-вывода;
- команды управления порядком исполнения команд (команды передачи управления) и некоторые другие.
Программа работы ЭВМ состоит из последовательности команд.
Под командой понимается информация, обеспечивающая выработку управляющих сигналов, формируемых в устройстве управления процессора, для выполнения машиной определенного действия.
Поле команды состоит из двух частей: операционной и адресной. В операционной части указывается код операции (КОП).
Код определяет действие, которое должна выполнить ЭВМ (арифметическое — сложение, вычитание, логическое — инверсия и т. д.).
Адресная часть команды содержит адреса операндов (чисел или символов), участвующих в операции. Под адресом понимается номер ячейки ОЗУ или ПЗУ, где записана необходимая для выполнения команды информация.
Таким образом, ЭВМ (точнее, процессор) выполняет действие, которое определяется кодом операции, над данными, местоположение которых указано в адресной части команды.
Количество указываемых в команде адресов может быть различным. В зависимости от числа адресов различают следующие форматы команд: одно-, двух- и трехадресные. Бывают и безадресные команды.
Трехадресная команда, выполняющая, например, операцию сложения, должна содержать код операции сложения и три адреса.
В случае двухадресной команды третий адрес отсутствует, и результат можно записать либо по второму адресу (с потерей информации, которая была там записана), либо оставить в регистре сумматора, где производилась операция сложения.
Тогда для освобождения регистра сумматора требуется дополнительная команда перезаписи числа по требуемому адресу. При организации сложения двух чисел, хранящихся по адресам А1 и А2 с записью результата в A3 с использованием одноадресных команд, требуется уже три команды.
Существуют безадресные команды, которые содержат только код операции, а необходимые данные заранее помещаются в определенные
Современные ЭВМ автоматически выполняют несколько сотен различных команд. Все машинные команды можно разделить на группы по видам выполняемых операций:
- операции пересылки данных;
- арифметические операции;
- логические операции;
- операции обращения к внешним устройствам ЭВМ;
- операции передачи управления;
- При проектировании новых процессоров разработчикам приходится решать сложную задачу выбора длины команды и определения списка необходимых команд (системы команд).
II. Кодовая таблица
Интересную историю привел в своей книге «Занимательная арифметика» Я. И. Перельман. В марте 1917 г. жители Петрограда были встревожены таинственными знаками, появившимися неизвестно откуда у дверей многих квартир. Знаки эти имели форму черточек, чередующихся крестами. Пошли зловещие слухи о грабителях, помечающих квартиры своих жертв, о германских шпионах и провокаторах. Я.И. Перельман распутал секрет этих знаков, после чего поместил в газете следующую заметку.
Таинственные знаки
«В связи с таинственными знаками, появившимися на стенах многих Петроградских домов, небесполезно разъяснить смысл одной категории подобных знаков, которые, несмотря на зловещее начертание, имеют самое невинное значение. Говорится о знаках такого типа:
+|| ++|||| +++|||
Подобные знаки замечены во многих домах на черных лестницах у дверей квартир. Обычно, знаки этого типа имеются у всех входных дверей данного дома, причем в пределах одного дома двух одинаковых знаков не наблюдается. Их мрачное начертание естественно внушает тревогу жильцам. Между тем, смысл легко раскрывается, если сопоставить их с номерами соответствующих квартир.
+|| ++|||| +++|||
24 33
Нетрудно догадаться, что кресты означают десятки, а палочки — единицы. Так оказалось во всех без исключения случаях, которые приходилось наблюдать. Своеобразная нумерация эта, очевидно, принадлежит дворникам-китайцам, не понимающим наших цифр. Появились эти знаки, конечно, давно, но только в дни Февральской революции обратили на себя внимание граждан».
кодовые таблицы
В памяти компьютера любой текст представляется последовательностью кодов символов, т. е. вместо самой буквы хранится ее номер в кодовой таблице. Изображение же букв и символов сформируется только в момент их вывода на экран или бумагу. Специальные стандарты определяют, какой код, какому символу будет соответствовать, иначе, (когда все пользуются собственными таблицами) обмен информацией практически невозможен.
Ниже приводится наиболее популярная из стандартизованных кодовых таблиц передачи символов, в которой для каждого символа отводится 8 бит (1 байт).
Таблица 1.
Таблица передачи символов ASCII

Если строго определены элементы алфавита и разрядность слов, получаемых с их помощью, то количество всех кодов можно вычислить, а, следовательно, составить их перечень в форме кодовой таблицы.
Таким образом, в кодовой таблице представлено определенное количество строк и только два столбца:
- в одном столбце указаны цифровые (в нашем случае двоичные) коды — «слова», как сочетания элементов алфавита, расположенные в определенной последовательности;
- в другом столбце — их значения (нецифровой смысл, т.
е. значения кодов).
Кодовая таблица — это совокупность цифровых (двоичных) кодов и их значений.
Стоит обратить внимание на то, что до сих пор мы оперировали цифрами и числами, получаемыми из этих цифр при помощи позиционной системы записи. Теперь оказалось, что на самом деле это — только половина кодовой таблицы. Рассмотрим построение кодовой таблицы. Первая проблема, которую нам предстоит решить, заключается в том, чтобы определить количество строк, т. е. мы сначала должны задаться количеством разрядов, как это выяснилось в предыдущем разделе. Но возникает следующий вопрос: а чем это определяется, какой необходимостью? Прежде всего, мы должны располагать предварительной информацией о количестве значений, которое нам предстоит кодировать. Если мы собрались кодировать только два значения, например «да» и «нет» или «черное» и «белое» т. е. такую информацию, которая состоит из двух сообщений, то потребуется всего один разряд (один бит), а соответствующая кодовая таблица будет состоять из двух строк.
Таблица 2.
Кодовая таблица для двух значений
|
Двоичные коды |
Значения кодов |
|
0 1 |
«Да!» «Нет!» |
Простота этой таблицы определяется тем, что в ней используются только элементы кодового алфавита. Если значений, которые надо кодировать, оказывается больше, чем два, то в этом случае элементы алфавита составляются в «слова», длина которых определяется разрядностью.
Например, если для кодирования требуется добавить значение, которое обычно присутствует в анкетах «Не знаю!», то одного разряда окажется недостаточно, необходимо задействовать два разряда
Таблица 3.
Кодовая таблица для трех значений
|
Двоичные коды |
Значения кодов |
|
00 01 10 11 |
«Да!» «Нет!» «Не знаю!» не используется |
Длина кодовой таблицы может быть произвольной, т. к. она определяется объемом информации, которая требует кодирования, но может быть ограничена возможностями технической реализации. Расчет длины кодовой таблицы составляет практически половину всей процедуры ее построения. Теперь большее внимание следует обратить на вторую часть кодовой таблицы, которая определяет значения каждого кода.
Однако следует отметить, что пользователям, которые применяют готовые технологии (программные приложения, общепринятые форматы и режимы), такими расчетами заниматься не приходится, поскольку давно разработаны стандартные кодовые таблицы. Вместе с тем, их ограничения, как правило, вызывают неприятие у лиц, которые не знакомы с особенностями логики, лежащей в основе компьютерных технологий.
Кодовая таблица — это внутреннее (закодированное) представление в машине букв, цифр, символов и управляющих сигналов. Так, латинская буква А в кодовой таблице представлена десятичным числом 65D (внутри ЭВМ это число будет представлено двоичным числом 01000001В), латинская буква С — числом 67D, латинская буква М — 77D и т.д. Таким образом, слово «САМАРА», написанное заглавными латинскими буквами будет циркулировать внутри ЭВМ в виде цифр.
Если говорить точнее, то внутри ЭВМ данное слово циркулирует в виде двоичных чисел: 01000011В-01000001В-01001101В-01000001В-01010000В-01000001В. Аналогично кодируются цифры (например, 1 — 49D, 2 — 59D) и символы (например, ! — 33D, + — 43D).
Наряду с алфавитно-цифровыми символами в кодовой таблице закодированы управляющие сигналы. Например, код 13D заставляет печатающую головку принтера вернуться к началу текущей строки, а код 10D перемещает бумагу, заправленную в принтер, на одну строку вперед. Кодовая таблица может быть представлена не только с помощью десятичной СС, но и при помощи шестнадцатеричной СС. Еще раз обращаем внимание на тот факт, что внутри ЭВМ циркулируют сигналы, представленные в двоичной системе счисления, а в кодовой таблице для большего удобства чтения пользователем — в десятичной или шестнадцатеричной СС. Каждая буква, цифра, знак препинания или управляющий сигнал кодируются восьмиразрядным двоичным числом. С помощью восьмиразрядного числа (однобайтового числа) можно представить (закодировать) 256 произвольных символов — букв, цифр и вообще графических образов.
В разных странах, на различных моделях ЭВМ, в разных операционных системах могут использоваться и разные варианты второй половины кодовой таблицы (их называют расширениями ASCII).
Например, таблица, которая используется в операционной системе MS-DOS, называется СР-866. При работе в операционной системе Windows используется таблица кодов СР-1251, в которой кодировка латинских букв совпадает с кодировкой таблиц СР-866 и ASCII, a вторая половина таблицы имеет собственную раскладку (кодировку) символов. Поэтому слово «САМАРА», написанное заглавными русскими буквами, будет иметь внутри ЭВМ другое представление.
Таким образом, внешне одинаковое слово (например, «САМАРА») внутри ЭВМ может быть представлено различным образом. Естественно, это вызывает определенные неудобства. При работе в Интернет национальный текст порой становится нечитаемым. Наиболее вероятной причиной в этом случае является несовпадение кодировок второй половины кодовых таблиц. Заметим, что если для составления писем, отправляемых по электронной почте, используется первая половина кодовой таблицы (латиница), то проблемы с кодировкой не возникают.
Общим недостатком всех однобайтовых кодовых таблиц (в них для кодировки используются восьмиразрядные двоичные числа) является отсутствие в коде символа какой-либо информации, которая подсказывает машине, какая в данном случае используется кодовая таблица.
Сообществом фирм Unicode предложена в качестве стандарта другая система кодировки символов.
В этой системе для представления (кодирования) одного символа используются два байта (16 битов), и это позволяет включить в код символа информацию о том, какому языку принадлежит символ и как его нужно воспроизводить на экране монитора или на принтере. Два байта позволяют закодировать 65 536 символов. Правда, объем информации, занимаемой одним и тем же текстом, увеличится вдвое. Зато тексты всегда будут «читаемыми» независимо от использованного национального языка и операционной системы.
III. Файловая система
Файловая система ЭВМ, как правило, имеет несколько дисков. Каждому диску присваивается имя, которое задается латинской буквой с двоеточием, например, А:, В:, С: и т. д. Стандартно принято, что А: и В: — это накопители на гибких магнитных дисках, а диски С:, D: и т. д. — жесткие диски, накопители на оптических дисках или электронные диски.
Электронные диски представляют собой часть оперативной памяти, которая для пользователя выглядит как ВЗУ. Скорость обмена информации с электронным диском значительно выше, чем с электромеханическим внешним запоминающим устройством. При работе электронных дисков не происходит износ электромеханических деталей. Однако после выключения питания информация на электронном диске не сохраняется.
Физически существующие магнитные диски могут быть разбиты на несколько логических дисков, которые для пользователя будут выглядеть на экране так же, как и физически существующие диски. При этом логические диски получают имена по тем же правилам, что и физически существующие диски. Проще говоря, логический диск — это часть обычного жесткого диска, имеющая собственное имя.
Диск, на котором записана операционная система, называется системным (или загрузочным) диском. В качестве загрузочного диска чаще всего используется жесткий диск С:. При лечении вирусов, системных сбоях загрузка операционной системы часто осуществляется с гибкого диска.
Выпускаются оптические диски, которые также могут быть загрузочными.
Форматирование — это подготовка диска для записи информации.
Во время форматирования на диск записывается служебная информация (делается разметка), которая затем используется для записи и чтения информации, коррекции скорости вращения диска. Разметка производится с помощью электромагнитного поля, создаваемого записывающей головкой дисковода. Запись информации осуществляется по дорожкам, причем каждая дорожка разбивается на секторы, например, по 1024 байта.
В процессе форматирования на диске выделяется системная область, которая состоит из трех частей: загрузочного сектора, таблицы размещения файлов и корневого каталога.
Загрузочный сектор (Boot Record) размещается на каждом диске в логическом секторе с номером 0. Он содержит данные о формате диска, а также короткую программу, используемую в процедуре начальной загрузки операционной системы.
Загрузочный сектор создается во время форматирования диска. Если диск подготовлен как системный (загрузочный), то загрузочный сектор содержит программу загрузки операционной системы. В противном случае он содержит программу, которая при попытке загрузки с этого диска операционной системы выводит сообщение о том, что данный диск не является системным.
Файл — это набор взаимосвязанных данных, воспринимаемых компьютером как единое целое, имеющих общее имя, находящихся на магнитном или оптическом дисках, магнитной ленте, в оперативной памяти или на другом носителе информации.
Файл обычно отождествляют с участком памяти (ВЗУ, ОЗУ, ПЗУ), где размещены логически связанные данные, имеющие общее имя. Файл хранится на носителе информации в двоичной системе счисления, и для ОС он представляется как совокупность связанных байтов.
В файлах могут храниться тексты программ, документы, данные и т. д.
Если файл большой, то он может занимать несколько дорожек.
При записи информации на новый (чистый) диск файлы располагаются последовательно друг за другом: от первой дорожки до последней.
Заметим, что файлы всегда занимают целое число кластеров, поэтому в одном кластере не могут одновременно размещаться два даже небольших файла. Обратите внимание на то, что если документ состоит всего из одной буквы, то файл все равно занимает на диске один отдельный кластер.
Имена файлов регистрируются на магнитных и оптических дисках в папках, каталогах (или директориях).
Термин «каталог» используется в операционных системах семейства DOS, термин «папка» — в операционных системах семейства Windows.
При многократной перезаписи и удалении файлов происходит фрагментация (дробление, разделение) дискового пространства. В результате файл может оказаться разорванным и располагаться в кластерах, находящихся на относительно большом расстоянии друг от друга. Считывание таких файлов существенно замедляется, так как дисководу необходимо дополнительное время для перемещения головок. Причина возникновения фрагментации состоит в том, что все файлы имеют, как правило, разную длину. Поэтому после удаления какого-то файла новый файл не может точно вписаться в освободившееся на диске место. Практически обязательно либо останется свободный участок диска, либо заполняются секторы, расположенные в другом месте диска (например, расположенные через несколько секторов или на других дорожках).
В составе операционной системы есть специальная программа (утилита), которая осуществляет дефрагментацию диска.
Эта утилита располагает тело файла в соседних секторах, тем самым ускоряет считывание информации (не нужно переходить на другие дорожки, пропускать чужие секторы) и уменьшает износ дисковода.
3.1 Назначение и функционирование файловой системы
В операционных системах файловая система относится к основным понятиям и определяется как общая система, которая устанавливает правила присвоения имен файлам, хранение, организацию и обработку файлов на носителях информации. Носители информации (ЗУ) реализуются в виде соответствующих технических средств, для хранения информации.
Microsoft
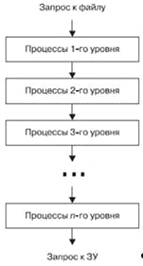
Рис. 4. Общая модель функционирования файловой системы
3.2 Файловая система FAT
формат команда кодовый файловый
Файловая система FAT используется ОС MS DOS и ОС Windows для упорядочения файлов и управления ими. В основу данной файловой системы положена таблица размещения FAT(File Allocation Table), которая представляет собой структуру данных, создаваемую ОС при форматировании данных на ЗУ. ОС хранит в таблице размещения файлов сведения о каждом файле, чтобы при необходимости можно было извлечь нужный файл.
Указанная файловая система вполне удовлетворяла требованиям своего времени в основном потому, что сама по себе очень компактна и проста. Благодаря этому она успешно использовалась и используется в НГМД. Для хранения файла в FAT может использоваться один или несколько кластеров, стандартный размер кластера 512 байт.
Существует несколько версий файловой системы FAT, среди которых наибольшее применение нашли файловые системы FAT 16 и FAT 32. Отличие этих файловых систем состоит в разрядности чисел, используемых в таблицах размещения файлов.
Заключение
В заключении можно сделать вывод, что организация данных в компьютере представляет собой текстовую и графическую информацию, хранящуюся в компьютере в виде файловых систем и папок. Файл в переводе с английского — это некая совокупность информации, документ, лист. Точнее было бы — папка, но папкой в иерархии размещения информации именуется совершенно другой уровень. Скорее — листок бумаги, на котором может быть написана некая информация. Неважно, что это — код программы или созданный вами текст.
В подавляющем большинстве случаев файл хранит в себе какой-то определенный тип данных — текст, графическую информацию, программный код и так далее (хотя бывают и некие «комбинированные» файлы, включающие, к примеру, картинку, текст и элемент программы).
Поэтому можно говорить о том, что существует множество типов файлов, которые пользователь и компьютер должны безошибочно различать.
Как правило, пользователь непосредственно работает лишь с двумя типами файлов: программами и документами. Первые используются, чтобы создавать вторые. Хотя сегодня очень редко встретишь программу, которая умещалась бы в одном файле. Вот почему и говорят сегодня о программных пакетах — т. е. наборах различных типов файлов, в совокупности образующих программу.
Литература
[Электронный ресурс]//URL: https://liarte.ru/referat/organizatsiya-dannyihinformatika/
1. Алексеев А.П. Информатика 2001. — М.: Солон — Р, 2001.
— Алексеев А.П. Информатика 2001 — М.: Солон
— Бройдо В.Л. Вычислительные машины, системы и сети. — СПб.:Питер, 2002.
— Информатика/Под ред. Н.В. Макаровой. — М.: Финансы и статистика, 2001.
— Острейковский В.А. Информатика. — М.: Высшая школа, 2001.
— Справочная система Microsoft Office
7. Бройдо В Л. Основы информатики. СПб.: СПб.ГИЭА, 2003.
— Каймин В.А. Информатика: Учебник. — М.: ИНФРА-М, 2000.
— Макарова Н.В.,Бройдо В.Л., Ильина О.П. и др. Информатика /Под ред. Н.В. Макаровой. М.: Финансы и статистика, 2002.
— Симонович С.В., Евсеев Г.А., Мураковский В.И. Информатика: базовый курс / Под ред. С.В. Симоновича. СПб.: Питер, 1999.
— Якубайтис Э.А. Информатика — Электроника — Сети. М.: Финансы и статистика 2003.