Основные структуры данных
Тема данной курсовой работы – «Основные структуры данных». Цель работы заключается в рассмотрении основных понятий, таких как информация, данные, структура данных, тип данных, модель данных, база данных, а также в выяснении их отличий и изучении процесса преобразования информации в структурированные данные.
Работа состоит из 29 страниц. Первая страница – титульный лист, на второй странице расположено оглавление. На третьей странице представлен реферат, а на четвертой – введение. Со страницы пятой по семнадцатую приведена теоретическая часть работы. На восемнадцатой странице размещено заключение. С девятнадцатой по двадцать шестую – практическая часть. Двадцатая седьмая страница содержит список используемой литературы. Со страницы двадцать восьмой по двадцать девятую расположены таблицы, которые являются приложением к работе. В тексте работы присутствуют ссылки на каждую из этих таблиц.
Теоретическая часть
Человечество на протяжении веков накапливало знания и информацию о мире, преобретая навыки работы и собирая сведения об окружающем нас мире. Вначале информация передавалась из поколения в поколение в виде преданий и устных рассказов. Появление книг позволило сохранить и передать информацию более надежно в письменном виде. Развитие электричества привело к появлению средств коммуникации, таких как телеграф, телефон, радио и телевидение, которые обеспечивают оперативную передачу и накопление информации.
С развитием прогресса информация начала накапливаться всё быстрее, и возник вопрос о её организации и обработке. В вычислительной технике появились новые способы упрощения хранения и обработки информации. С развитием микропроцессоров стали появляться более совершенные компьютеры и программное обеспечение. Создание программ, способных обрабатывать большие объемы информации, привело к появлению информационных систем.
Основной целью любой информационной системы является обработка данных о реальном мире и предоставление нужной информации о них человеку.
Классификация структур данных
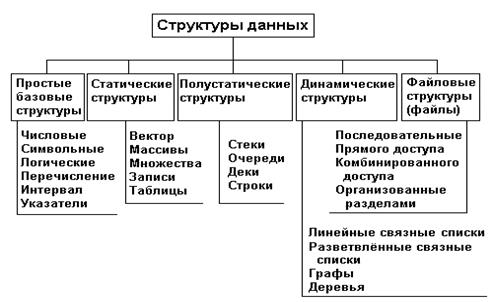
В основной части работы рассматривается классификация структур данных и дается подробное описание каждого из классов. Структуры данных могут быть разделены на несколько типов, включая:
- Линейные структуры данных, такие как списки и стеки.
- Древовидные структуры данных, включающие бинарные деревья и кучи.
- Графовые структуры данных, такие как графы и диаграммы.
- Хеш-таблицы и другие хеш-структуры данных.
Каждая из этих структур данных имеет свои особенности и применяется в различных областях информационных технологий.
База данных курсовых работ
... положено реляционной СУБД. К этим данным относится не только информация в таблицах, но и другие объекты базы данных, например форма, отчет или страница. Для выполнения почти всех основных ... реляционной структуре. В них тем или иным путем решаются специфические проблемы параллельных процессов, целостности (правильности) и безопасности данных, а также санкционирования доступа. В данной курсовой работе ...
Практическая часть
В практической части работы приведены примеры использования основных структур данных. Рассмотрены конкретные ситуации, при которых применение определенной структуры данных является наиболее эффективным.
Заключение
В результате исследования были рассмотрены основные понятия, классификация и характеристики структур данных. Был проанализирован процесс преобразования информации в структурированные данные. Практическая часть работы позволила применить полученные знания на практике и продемонстрировать эффективность использования структур данных в различных ситуациях.
Список используемой литературы
Для выполнения данной работы использовался следующий список литературы:
- Название книги 1
- Название книги 2
- Название книги 3
Приложения
В приложении к работе представлены таблицы, которые иллюстрируют примеры использования структур данных, описанных в теоретической и практической части работы.
Различия между данными и информацией
Данные — это информация в формализованном виде, предназначенная для обработки техническими системами. Информация, в свою очередь, представляет собой совокупность фактов, событий и явлений, которые необходимо зарегистрировать и обработать.
Процесс обработки информации
Данные хранят информацию, но как только начинают использоваться, преобразуются в информацию. В процессе обработки информация изменяется по структуре и форме. Структура информации классифицируется на формальную и содержательную, ориентированную на форму представления и содержание соответственно.
Виды форм представления информации
-
По способу отображения:
- символьная (знаки, цифры, буквы);
- графическая (изображения);
- текстовая (набор букв, цифр);
- звуковая.
-
По месту появления:
- внутренняя (выходная);
- внешняя (входная).
-
По стабильности:
- постоянная;
- переменная.
-
По стадии обработки:
- первичная;
- вторичная.
Классификация элементов объекта
Для описания структур данных и алгоритмов программ используются системы формальных обозначений, называемые языками программирования, где каждое предложение имеет точное и однозначное значение.
Физическая структура данных представляет собой основной элемент информационной системы. Она служит для организации и хранения данных в компьютере. Структуры данных могут быть простыми и интегрированными. Простые структуры данных не могут быть разделены на составные части, большие чем биты, в то время как интегрированные структуры состоят из других структур данных.
Структуры данных могут быть также классифицированы как связные и несвязные, статические и оперативные, линейные и нелинейные. Связные структуры данных имеют связи между элементами, а несвязные — нет. Статические структуры данных имеют фиксированное количество элементов, в то время как оперативные имеют изменяемое количество элементов. Линейные структуры данных организованы последовательно, в то время как нелинейные имеют более сложные связи между элементами.
Иерархическая модель данных. Структуры данных
... в точности одного предка. Иерархическая модель представляет собой связный неориентированный гpaф древовидной структуры, объединяющий сегменты. Иерархическая база данных состоит из упорядоченного набора деревьев. Организация данных в СУБД иерархического типа определяется в терминах: ...
В языках программирования понятие «структуры данных» тесно связано с понятием «типы данных». Тип данных определяет структуру хранения данных, множество допустимых значений и операций, применимых к этим данным.
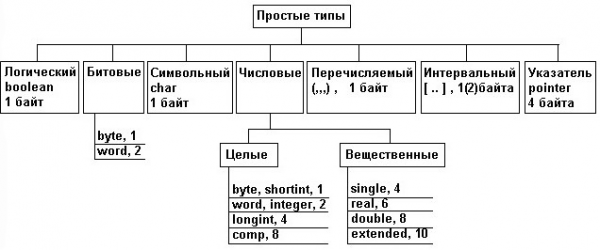
Простые структуры данных, также известные как примитивные или базовые структуры, являются основой для более сложных структур. Они описываются с помощью простых типов данных. К таким типам относятся числовые, битовые, логические, символьные, перечисляемые, интервальные и указатели. Примитивные типы данных определяют размер памяти, необходимый для хранения данных типа.
Числовые типы данных включают целые и вещественные типы. Целые типы представляют целые числа, а вещественные типы — числа с плавающей точкой.
Также существуют типы данных, которые позволяют работать с отдельными битами данных. Такие типы данных используются в системном программировании, когда необходимо обрабатывать разряды данных независимо друг от друга.
Использование структур данных является важной частью разработки программных систем. Умение выбрать подходящую структуру данных для определенной задачи может существенно улучшить производительность и эффективность программы. В дальнейшем будут рассмотрены примеры различных структур данных и их применение.
Логические и символьные типы данных
Значениями логического типа BOOLEAN может быть одна из заранее объявленных констант false (ложь) или true (истина).
Данные логического типа занимают один байт памяти. При этом значении false соответствует нулевое значение байта, а значению true соответствует любое ненулевое значение байта. Над логическими типами возможны операции нулевой алгебры — НЕ (not), ИЛИ (or), И (and), исключающее ИЛИ (xor).
В этих операциях операнды логического типа рассматриваются как единое целое. Результаты логического типа получаются при сравнении данных любых типов.
Значением символьного типа char являются символы из некоторого предопределенного множества. Множество символов состоит из 256 разных символов, упорядоченных определенным образом, и содержит символы заглавных и строчных букв, цифр и других символов, включая специальные управляющие символы. Значение символьного типа char занимает в памяти 1 байт.
Перечислимый тип
Перечислимый тип представляет собой упорядоченный тип данных, определяемый программистом, т.е. программист перечисляет все значения, которые может принимать переменная этого типа. Значения являются неповторяющимися, количество которых не может быть больше 256.
Указатели
Тип указателя представляет собой адрес ячейки памяти. При программировании на низком уровне — в машинных кодах, на языке Ассемблера и на языке C, который специально ориентирован на системных программистов, работа с адресами составляет значительную часть программных кодов.
Структуры данных в языках программирования
Статические структуры в языках программирования связаны со структурированными типами. Структурированные типы в языках программирования являются средствами интеграции, позволяющими строить структуры данных любой сложности. К ним относятся массивы, записи и множества.
Вектор (одномерный массив)
Вектор — структура данных с фиксированным числом элементов одного типа, каждый из которых имеет уникальный номер и имя в рамках вектора.
Динамические структуры данных в языке Паскаль
... с различными типами. Значения ссылочных типов создаются всякий раз, когда динамически размещается какой-либо элемент данных. Для динамического размещения данных в языке Паскаль используется стандартная ... ссылки значению nil. Следует отметить, что компоненты динамической структуры данных всегда относятся к комбинированному типу (reсord), поскольку кроме смысловой информации должны обязательно ...
Массивы
Массив — структура данных с фиксированным набором элементов одного типа, каждый из которых имеет уникальный набор значений индексов. Обращение к элементам массива происходит по имени и значениям индексов.
Множества
Множество может иметь базовый тип, который определяется множеством значений. Возможны числовые, символьные и перечислимые множества.
Записи
Запись — упорядоченное множество полей различных типов данных, включая интегрированные структуры данных. Это представляет собой конечную структуру.
Полустатические структуры данных
Стек — последовательный список переменной длины, операции включения и исключения элементов выполняются только с одной стороны списка, называемой вершиной стека. Основные операции — включение и исключение элементов, дополнительные — определение количества элементов и очистка стека.
Стек — это структура данных, которая представляет собой последовательность элементов, где добавление новых элементов происходит только на одном конце, называемом вершиной, а удаление элементов — тоже только с этого конца. Другими словами, принцип работы стека основан на принципе «последним вошел — первым вышел» (Last In First Out — LIFO).
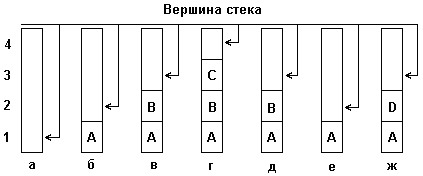
Для наглядности рассмотрим небольшой пример, демонстрирующий принцип включения элементов в стек и исключения элементов из стека. На рис. 3 (а, б ,с) изображены состояния стека.
а) На рисунке изображен пустой стек, в котором нет ни одного элемента.
б, в, г) Последовательно добавляем в стек элементы с именами ‘A’, ‘B’, ‘C’. В результате стек содержит три элемента: ‘A’ на дне стека, ‘B’ находится над ‘A’, а ‘C’ находится на вершине стека.
д, е) Последовательно удаляем из стека элементы ‘C’ и ‘B’. После каждой операции удаления состояние стека меняется. Сначала удаляется элемент ‘C’, затем — элемент ‘B’. Таким образом, в стеке остается только элемент ‘A’.
ж) Затем мы включаем в стек элемент ‘D’. После этой операции состояние стека изменяется, и теперь в нем содержится элемент ‘A’ на дне и элемент ‘D’ на вершине стека.
Как видно из рис. 3, стек можно представить в виде стопки книг, лежащей на столе. Каждая книга имеет свое название, например A, B, C, D. Если на столе нет книг, то можно сказать, что стек пуст. Последовательное добавление элементов в стек аналогично тому, как мы кладем книги одну на другую, и тем самым формируем стопку книг или стек с элементами. Удаление элементов из стека происходит аналогично — мы удаляем один элемент за другим, начиная с вершины стека или снимаем одну книгу со стопки.
Очередь FIFO (First In First Out) — это структура данных, в которой элементы добавляются в одном конце очереди (конец), а удаляются — с другого конца очереди (начало).
Основные операции над очередью включают элементы в ее конец, исключают элементы из ее начала, определяют ее размер, очищают ее, а также выполняют неразрушающее чтение.
Дек (двусторонняя очередь) — это структура данных, где как добавление, так и удаление элементов могут осуществляться с обоих концов списка. Операции над деком включают элементы справа и слева, удаляют элементы справа и слева, определяют его размер и могут выполнить очистку.
Строка представляет собой линейно упорядоченную последовательность символов, принадлежащих конечному множеству символов, которое называется алфавитом. Обычно под строками понимают текстовые строки, которые состоят из символов, входящих в алфавит определенного языка, а также цифр, знаков препинания и других служебных символов. Базовые операции над строками включают определение длины строки, присваивание строк, конкатенацию (сцепление) строк, выделение подстроки и поиск вхождения символов.
Динамические структуры данных
Достоинства связного представления данных: в возможности обеспечения значительной изменчивости структур; размер структуры ограничивается только доступным объёмом машинной памяти; при изменении логической последовательности элементов структуры требуется не перемещение данных в памяти, а только коррекция указателей. Вместе с тем связное представление не лишено и недостатков: работа с указателями требует, как правило, более высокой квалификации от программиста; на поля связок расходуется дополнительная память; доступ к элементам связной структуры может быть менее эффективным по времени.
Связные линейные списки.
линейным
На рис. 4 приведена структура односвязного списка. На нем поле INF — информационное поле, данные, NEXT — указатель на следующий элемент списка. В поле указателя последнего элемента списка находится специальный признак nil, свидетельствующий о конце списка.
двухсвязный список
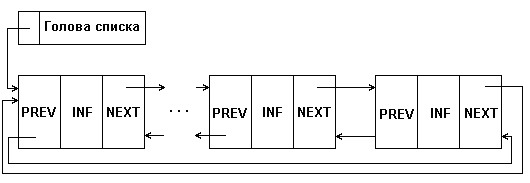
Разновидностью рассмотренных видов линейных списков является кольцевой
список, который может быть организован на основе как односвязного, так и
двухсвязного списков, как показано на рис. 6.
Линейные списки находят широкое применение в приложениях, где непредсказуемы требования на размер памяти, необходимой для хранения данных; большое число сложных операций над данными, особенно включений и исключений.
Nелинейным разветвленным списком является список, элементами которого могут быть тоже списки. Если один из указателей каждого элемента списка задает порядок обратный к порядку, устанавливаемому другим указателем, то такой двусвязный список будет линейным. Если же один из указателей задает порядок произвольного вида, не являющийся обратным по отношению к порядку, устанавливаемому другим указателем, то такой список будет нелинейным.
В обработке нелинейный список определяется как любая последовательность атомов и списков (подсписков), где в качестве атома берется любой объект, который при обработке отличается от списка тем, что он структурно неделим.
Нелинейные структуры данных
ориентированными
Дерево — это граф, который характеризуется следующими свойствами:
корнем
В бухгалтерии ООО «Снежок» производится расчет отчислений по каждому сотруднику предприятия. Это важная задача, которая требует точности и аккуратности. Для решения данной задачи необходимо использовать структуры данных, которые помогут организовать и обработать информацию о сотрудниках и их отчислениях.
В данной работе мы будем рассматривать различные структуры данных, которые могут быть использованы для решения подобных задач. В частности, мы рассмотрим структуры данных всех классов памяти ЭВМ: простые, статические, полустатические, динамические и нелинейные.
Структуры данных представляют собой абстрактные структуры или классы, которые позволяют организовать данные и выполнять различные операции над ними. Они являются ключевым инструментом для эффективного программирования и могут существенно влиять на производительность программы.
Для решения задачи расчета отчислений по каждому сотруднику предприятия можно использовать различные структуры данных, такие как массивы, списки, деревья и т.д. Каждая из этих структур имеет свои преимущества и недостатки, и выбор конкретной структуры зависит от требований задачи.
Например, для хранения информации о сотрудниках и их отчислениях можно использовать массивы. Массивы позволяют хранить данные в упорядоченной последовательности и обращаться к ним по индексу. Однако, массивы имеют фиксированный размер и не могут быть изменены в процессе выполнения программы.
Другим вариантом является использование списков. Списки позволяют хранить данные в виде связанной последовательности элементов, каждый из которых содержит ссылку на следующий элемент. Это позволяет легко добавлять и удалять элементы из списка, но при этом доступ к элементам осуществляется последовательно.
Также можно рассмотреть использование деревьев. Деревья представляют собой иерархическую структуру данных, в которой каждый элемент имеет ссылку на своих потомков. Это позволяет эффективно организовать данные и быстро выполнять операции поиска и сортировки.
В данной работе мы будем анализировать различные операции, выполняемые структурами данных, и оценивать их эффективность. Для этого мы будем рассматривать время выполнения операций на различных размерах данных и сравнивать результаты.
Таким образом, решение задачи расчета отчислений по каждому сотруднику предприятия требует выбора подходящей структуры данных. В данной работе мы будем исследовать различные структуры данных и их применение для решения данной задачи.
- в федеральный бюджет;
- фонды обязательного медицинского страхования (ФФОМС – федеральный, ТФОМС – территориальный);
- фонд социального страхования (ФСС).
Процентные ставки отчислений приведены на рис. 6.1 . Данные для расчета отчислений в фонды по каждому сотруднику приведены на рис. 6.2 .
1. Построить таблицы по приведённым ниже данным.
2. Выполнить расчёт размеров отчислений с заработной платы по каждому сотруднику предприятия, данные расчета занести в таблицу ( рис.6.2 ).
единого социального налога
4. Сформировать и заполнить ведомость расчета ЕСН ( рис 6.3 ).
5. Результаты расчета ЕСН по каждому сотруднику за текущий месяц представить в графическом виде.
СТАВКИ ЕСН
|
Фонд, В который производится отчисление |
Ставка, % |
|
ТФОМС |
2,00 |
|
Федеральный бюджет |
20,00 |
|
ФСС |
3,20 |
|
ФФОМС |
0,80 |
|
ИТОГО |
26,00 |
Рис. 6.1.
|
Табельный номер |
ФИО сотрудника |
Начислено за Месяц, руб. |
Федеральный Бюджет, руб. |
ФСС, руб. |
ФФОМС, руб. |
ТФОМС, руб. |
Итого, руб. |
|
001 |
Иванов И.И. |
15 600,00 |
|||||
|
002 |
Сидоров А.А |
12 300,00 |
|||||
|
003 |
Матвеев К.К. |
9 560,00 |
|||||
|
004 |
Сорокин М.М. |
4 620,00 |
|||||
|
005 |
Петров С.С. |
7 280,00 |
Рис. 6.2.
|
ООО «Снежок»
ВЕДОМОСТЬ РАСЧЕТА ЕСН
|
||||||||||||||||||||||||||||||
Рис. 6.3.
Описание алгоритма решения задачи
1. Запустить табличный процессор MS Excel.
2. Создать книгу с именем «ООО Снежок»
Ставки ЕСН., Ставки ЕСН
5. Заполнить таблицу процентных ставок отчислений исходными данными (рис. 7.1).
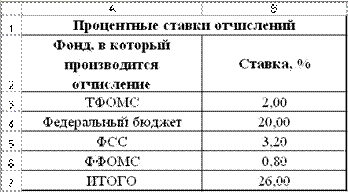
Рис. 7.1.
Ставки ЕСН, Данные для расчета ЕСН за текущий месяц по каждому сотруднику
|
Колонка Электронной таблицы |
Наименование (реквизит) |
Тип данных |
Формат данных |
|
|
длина |
точность |
|||
|
A |
Табельный номер |
000 |
3 |
|
|
B |
ФИО сотрудника |
текстовой |
50 |
|
|
C |
Начислено за месяц, руб. |
денежный |
20 |
2 |
|
D |
Федеральный Бюджет, руб. |
денежный |
20 |
2 |
|
E |
ФСС, руб. |
денежный |
20 |
2 |
|
F |
ФФОМС, руб. |
денежный |
20 |
2 |
|
G |
ТФОМС, руб. |
денежный |
20 |
2 |
|
H |
Итого, руб. |
денежный |
20 |
2 |
рис. 7.2.
Сотрудники., Сотрудники, Данные для расчета ЕСН за текущий месяц по каждому сотруднику
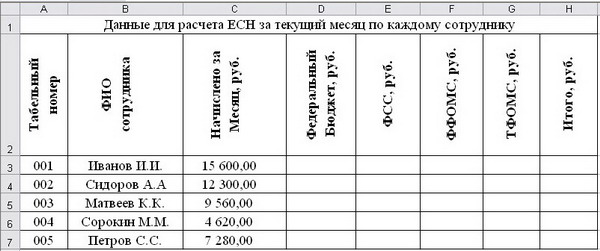
Рис. 7.3.
Данные для расчета ЕСН за текущий месяц по каждому сотруднику, Сотрудники, Федеральный бюджет, руб.
Занести в ячейку D3 формулу: =ПРПЛТ(C3;1;1;-‘Ставки ЕСН’!B4)
Занести в ячейку D4 формулу: =ПРПЛТ(C4;1;1;-‘Ставки ЕСН’!B4)
Занести в ячейку D5 формулу: =ПРПЛТ(C5;1;1;-‘Ставки ЕСН’!B4)
Занести в ячейку D6 формулу: =ПРПЛТ(C6;1;1;-‘Ставки ЕСН’!B4)
Занести в ячейку D7 формулу: =ПРПЛТ(C7;1;1;-‘Ставки ЕСН’!B4)
ФСС, руб.
текущий месяц по каждому сотруднику
Занести в ячейку E3 формулу: =ПРПЛТ(C3;1;1;-‘Ставки ЕСН’!B5)
Занести в ячейку E4 формулу: =ПРПЛТ(C4;1;1;-‘Ставки ЕСН’!B5)
Занести в ячейку E5 формулу: =ПРПЛТ(C5;1;1;-‘Ставки ЕСН’!B5)
Занести в ячейку E6 формулу: =ПРПЛТ(C6;1;1;-‘Ставки ЕСН’!B5)
Занести в ячейку E7 формулу: =ПРПЛТ(C7;1;1;-‘Ставки ЕСН’!B5)
ФФОМС, руб.
Занести в ячейку F3 формулу: =ПРПЛТ(C3;1;1;-‘Ставки ЕСН’!B5)
Занести в ячейку F4 формулу: =ПРПЛТ(C4;1;1;-‘Ставки ЕСН’!B5)
Занести в ячейку F5 формулу: =ПРПЛТ(C5;1;1;-‘Ставки ЕСН’!B5)
Занести в ячейку F6 формулу: =ПРПЛТ(C6;1;1;-‘Ставки ЕСН’!B5)
Занести в ячейку F7 формулу: =ПРПЛТ(C7;1;1;-‘Ставки ЕСН’!B5)
ТФОМС, руб.
Занести в ячейку G3 формулу: =ПРПЛТ(C3;1;1;-‘Ставки ЕСН’!B5)
Занести в ячейку G4 формулу: =ПРПЛТ(C4;1;1;-‘Ставки ЕСН’!B5)
Занести в ячейку G5 формулу: =ПРПЛТ(C5;1;1;-‘Ставки ЕСН’!B5)
Занести в ячейку G6 формулу: =ПРПЛТ(C6;1;1;-‘Ставки ЕСН’!B5)
Занести в ячейку G7 формулу: =ПРПЛТ(C7;1;1;-‘Ставки ЕСН’!B5)
Итого, руб.
Занести в ячейку H3 формулу: =СУММ(D3:G3)
Размножить введённую в ячейку H3 формулу для остальных ячеек (с H4 по H7) данной графы.
Таким образом, будет выполнен цикл , управляющим параметром которого является номер строки.
Данные для расчета ЕСН за текущий месяц по каждому
сотруднику
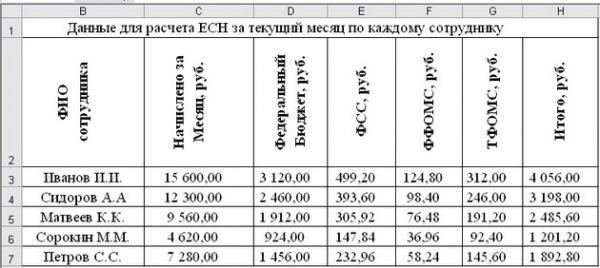
Рис. 7.4.
Данные для расчета ЕСН за текущий месяц по каждому сотруднику, Сотрудники, Ведомость, Ведомость, Данные для расчета ЕСН за текущий месяц по каждому сотруднику, Федеральный бюджет, руб.
Занести в ячейку F16 формулу: =Сотрудники!D3
Размножить введённую в ячейку F16 формулу для остальных ячеек (с F17 по F20) данной графы.
ФСС, руб.
Занести в ячейку G16 формулу: =Сотрудники!E3
Размножить введённую в ячейку G16 формулу для остальных ячеек (с G17 по G20) данной графы.
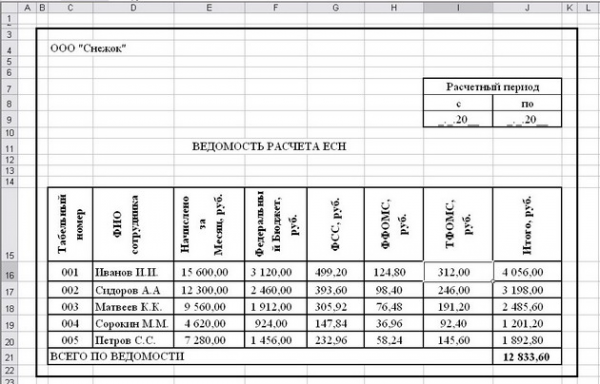
Рис. 7.5.
Ведомость
ФФОМС, руб.
Занести в ячейку H16 формулу: =Сотрудники!F3
Размножить введённую в ячейку H16 формулу для остальных ячеек (с H17 по H20) данной графы.
ТФОМС, руб.
Занести в ячейку I16 формулу: =Сотрудники!G3
Размножить введённую в ячейку I16 формулу для остальных ячеек (с G17 по G20) данной графы.
Итого, руб.
J16 формулу: =Сотрудники!H3
Размножить введённую в ячейку J16 формулу для остальных ячеек
(с J17 по J20) данной графы.
Занести в ячейку J21 формулу: =СУММ(J16:J20)
ООО Снежок
23. Полученный новый лист переименовать в лист с названием График .
24. Результаты расчета ЕСН по каждому сотруднику представить в графическом виде на рабочем листе График MS Excel (рис. 7.6).
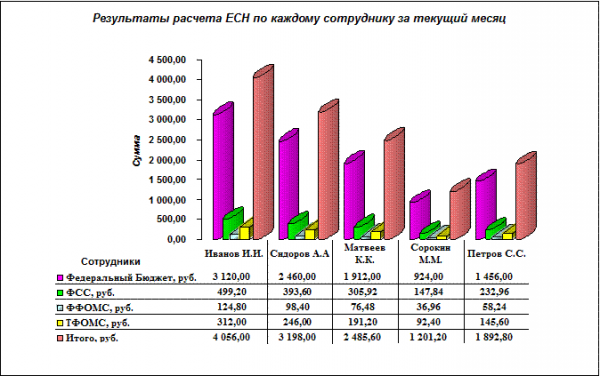
Рис. 7.6.
на рабочем столе График MS Excel
1. Башлы П.Н. Информатика /П.Н. Башлы. – Ростов н/Д: Феникс, 2006.- 249с.
2. Вирт Н. Алгоритмы и структуры данных./Пер. с англ. — М.: Мир, 1999.–360с.
3. Евсюков В.В. Экономическая информатика: Учеб. пособие – Тула: Издательство «Гриф и К», 2003. – 371с.: ил. базы данных.
4. Информатика: Практикум по технологии работы на комп. / Под ред. Н.В. Макаровой. — М.: Финансы и статистика, 2000. — 384с.
5. Модели и структуры данных В.Д. Далека, А.С. Деревянко, О.Г. Кравец, Л.Е. Тимановская. Учебное пособие. Харьков: ХГПУ, 2000. — 241с.
6. Меняев М.Ф. Информационные технологии управления: Учеб. пособие. В 3 кн.: Книга 1: Информатика. – М.: Омега – Л, 2003. — 464с.
7. Меняев М.Ф. Информационные технологии управления: Учеб. пособие. В 3 кн.: Книга 2: Информ. Ресурсы. – М.: Омега – Л, 2003. — 432с.
8. Практикум по эконом. информатике: Учеб. пособие: В 3-х ч. – Ч.I / Под ред. Е.Л. Шуремова, Н.А. Тимаковой, Е.А. Мамонтовой – М.: Финансы и статистика; Перспектива, 2002. – 300с.
9. Советов Б. Я.. Информационные технологии. Учебник для студентов вузов. 2006. — 263 с.
10. Степанов А.Н. Информатика: Учебник для вузов. 5-е изд. – Спб.: Питер, 2007. – 765с.: ил. база данных.
11. Уоллес Вонг. Основы программирования для «чайников». ДИАЛЕКТИКА. Москва – Санкт-Петербург – Киев. 2001. – 335 с.
12. Интернет.
Приложение №1
Рис. 1. Классификация структур данных
Приложение №2
Рис. 2. Структура простых типов PASCAL
Приложение №3
Рис. 3. Включение и исключение элементов из стека
Приложение №4
Рис. 4 Структура односвязного списка

Приложение №5
Рис. 5 Структура двухсвязного списка
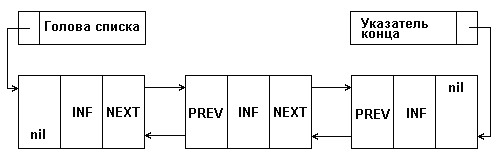
Приложение №6
Рис. 6 Структура кольцевого двухсвязного списка
См. Приложение 1 (стр. 28)
См. Приложение 2 (стр. 28)
См. Приложение 3 (стр. 29)
См. Приложение 4 (стр. 29)
См. Приложение 5 (стр. 29)
См. Приложение 6 (стр. 29)