Структура данных – это организационная схема записи или массива, в соответствии с которой упорядочены данные, с тем, чтобы их можно интерпретировать и выполнять над ними определённые операции. Это исполнитель, который организует работу с данными, включая их хранение, добавление и удаление, модификацию, поиск. Её можно рассматривать, как своего рода склад или библиотеку.
Структура данных поддерживает определённый порядок доступа к ним. Понятие структуры данных можно определить, как совокупность внешних связей между элементами данных, которые на принятом уровне рассмотрения можно считать неделимыми, элементарными.
Работа с большими наборами данных автоматизируется проще, когда данные упорядочены, то есть образуют заданную структуру. Существуют следующие основные типы структур данных:
- списковые
- древовидные или иерархические
- сетевые
• табличные
1. Информация и данные
В информатике различают два понятия «данные» и «информация». Данные представляют собой информацию, находящуюся в формализованном виде и предназначенную для обработки техническими системами. Под информацией понимается совокупность представляющих интерес фактов, событий, явлений, которые необходимо зарегистрировать и обработать. Информация в отличие от данных – это то, что нам интересно, что можно хранить, накапливать, применять и передавать. Данные только хранятся, а не используются. Но как только данные начинают использоваться, то они преобразуются в информацию. В процессе обработки информация изменяется по структуре и форме. Признаками структуры является взаимосвязь элементов информации. Структура информации классифицируется на формальную и содержательную. Формальная структура информации ориентирована на форму представления информации, а содержательная – на содержание.
Виды форм представления информации:
- По способу отображения: символьная (знаки, цифры, буквы); графическая (изображения); текстовая (набор букв, цифр) и звуковая.
- По месту появления: внутренняя (выходная) и внешняя (входная).
- По стабильности: постоянная и переменная.
- По стадии обработки: первичная и вторичная.
Независимо от содержания и сложности любые данные в памяти ЭВМ представляются последовательностью двоичных разрядов, или битов, а их значениями являются соответствующие двоичные числа. Для человека описывать и исследовать сколько-нибудь сложные данные в терминах последовательностей битов весьма неудобно. Более крупные и содержательные, нежели бит, «строительные блоки» для организации произвольных данных получаются на основе понятия «структуры данного».
Базы данных и управление ими
... хранения информации в файлах ЭВМ дешевле, чем на бумаге. Базы данных позволяют хранить, структурировать информацию и извлекать оптимальным для ... использовать восемь групп АИС, в соответствии со структурой предприятия. Взаимосвязи АИС "Основное производство и контроль ... для получения необходимой информации, а также упрощают доступ и ведение, поскольку они основываются на комплексной обработке данных ...
2. Классификация структур данных
Структуры данных служат материалами, из которых строятся программы. Как правило, данные имеют форму чисел, букв, текстов, символов и более сложных структур типа последовательностей, списков и деревьев.
структурой данных
Физическая структура данных
абстрактной
Простыми
несвязные структуры
статические
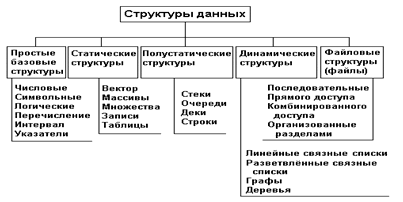
Рис. 1. Классификация структур данных
оперативными структурами
линейные и нелинейные
В языках программирования понятие «структуры данных» тесно связано с понятием «типы данных». Любые данные, т.е. константы, переменные, значения функций или выражения, характеризуются своими типами.
Информация по каждому типу однозначно определяет:
1) структуру хранения данных указанного типа, т.е. выделение памяти и представление данных в ней, с одной стороны, и интерпретирование двоичного представления, с другой;
2) множество допустимых значений, которые может иметь тот или иной объект описываемого типа;
3) множество допустимых операций, которые применимы к объекту описываемого типа.
3. Характеристики основных типовых структур
3.1 Линейные и нелинейные
Все структуры данных можно подразделить на линейные и нелинейные. Отличия в том, что у линейных все элементы структуры расположены на одном уровне, у нелинейных – на нескольких уровнях.
Структуры данных также можно разделить на два больших класса по признаку физического размещения в памяти:
1) физически последовательные структуры, или просто последовательные структуры данных (ПДС);
— Среди структур данных с произвольным размещением элементов, прежде всего, выделяются списковые структуры данных (ССД), или просто списки. К линейным структурам данных относятся ПДС и простые списки, они также называются строками, или строчными структурами.
ПДС реализуют естественное отношение порядка на множестве данных в среде хранения: «следующий» означает расположенный в памяти непосредственно вслед за предыдущим. Если этот естественный порядок совпадает с логическим отношением порядка на множестве элементов данных (чаще всего, когда у элементов данных выделяются ключевые атрибуты, он устанавливается в соответствии со значениями ключа), то такие разновидности ПДС называют упорядоченными (сортированными), если не совпадает – неупорядоченными. Служебная информация для описания ПДС обычно содержит сведения о количестве элементов множества данных, размерах (длине) элементов, о расположении ключа или ключей (если элементами являются записи) и их размерах, адресе первого элемента множества данных, и другие.
В зависимости от разнообразия длин данных и способа указания длины записи ПДС подразделяются на следующие разновидности:
Иерархическая модель данных. Структуры данных
... одного предка. Иерархическая модель представляет собой связный неориентированный гpaф древовидной структуры, объединяющий сегменты. Иерархическая база данных состоит из упорядоченного набора деревьев. Организация данных в СУБД иерархического типа определяется в терминах: элемент, агрегат, ...
- ПДС с фиксированной длиной элементов;
- ПДС с элементами переменной длины;
- ПДС с элементами неопределённой длины.
Данные фиксированной длины имеют одинаковую заранее известную длину и обеспечивают прямой доступ к каждому элементу, адрес которого вычисляется. Элементы длины у которых указаны явно ( например, специальными служебными полями в специальной служебной записи), называются ПДС с элементами переменной длины. Если вместо явного указания длины используется заранее установленный символ (разделитель), указывающий на конец элемента данных, то ПДС называются — ПДС с элементами неопределённой длины.
Особая разновидность ПДС – очереди. В них для пользователя (при обращении к ПДС за данными или при добавлении новых данных) доступен только первый или (и) последний элемент данных. Вся остальная служебная информация скрыта от него и доступна только управляющей очередями программе. Разновидности очередей определяются конкретным вариантом доступного для поступления и доступного для обработки элемента. Наиболее распространены следующие разновидности очередей:
- магазин или стек – соответствует принципу «первый вошёл, последний вышел»;
- очередь (т.е. очередь в узком смысле в отличие от всей совокупности этого подкласса ПДС), соответствует принципу «первый вошёл, первый вышел»;
- дек – двусторонняя очередь, структура, позволяющая добавлять и извлекать элементы, как в начале, так и в конце последовательности данных.
3.2 Списковые структуры данных
Списковые структуры данных – это множество физически не связанных элементов, для которых отношение следования определено с помощью специальных адресов связи. В адресе связи указывается адрес элемента, следующего в логическом порядке хранения за данным элементом.
Элементы ССД могут быть двух типов: простые, логически не делимые (их называют подсписками) или сложные – совокупность простых и сложных меньшого объёма. В простые ССД (строки или цепи) входят только простые элементы. В сложные ССД входят и простые, и сложные элементы.
Каждый элемент ССД содержит собственную информацию – значение элемента и ассоциативную информацию – адреса связи с другими элементами структуры, которые объединяются в звенья связи.
По виду взаимосвязи элементов различают однонаправленные, двунаправленные и кольцевые списковые структуры:
- В однонаправленных списках реализуется взаимосвязь между элементами типа «следующий». Каждый элемент такого списка содержит указатель с адресом следующего элемента. Последний элемент имеет в указателе вместо адреса связи специальный знак – признак конца списка. Указатель списка содержит адрес его первого элемента. Длязадания однонаправленной списковой структуры требуется следующая ассоциативная информация:
- указатель списка с адресом первого элемента;
— звено связи элементов, в которых для простого элемента содержаться адрес следующего элемента списка и адрес значения элемента, а для сложного элемента – адрес следующего элемента списка и адрес первого элемента подсписка.
Динамические структуры данных в языке Паскаль
... какой-либо элемент данных. Для динамического размещения данных в языке Паскаль используется стандартная ... структура данных - последовательность (файл), т.е. простейший вид структуры, допускающей построение типов с бесконечным кардинальным числом. В связи с этим, естественно, возникает вопрос о существовании структуры данных ... памяти только для хранения адреса динамически размещаемой компоненты. ...
- Двунаправленные списки ориентированы на обработку, как в прямом, так и в обратном направлении. Для этого в звенья связи дополнительно вводится адрес, реализующий связь типа «предыдущий». Для задания двунаправленной списковой структуры необходима ассоциативная информация:
- указатель списка, содержащий адрес первого и последнего элементов;
- звенья связи элементов, для простого элемента это звено содержит адреса
предыдущего и последующего элементов, а также адрес значения элемента, для сложного элемента в звене связи содержится адрес последующего и предыдущего элементов списка и адреса первого и последнего элемента подсписка.
- Кольцевой называется такая списковая структура, элементы которой могут быть просмотрены в циклической последовательности заданное число раз. Кольцевые структуры также могут быть, как однонаправленными, так и двунаправленными, могут быть простыми (строчными) и сложными (редко используются на практике).
Для задания однонаправленной простой кольцевой структуры необходимо иметь ассоциативную информацию:
- указатель строки, который содержит адрес указателя начала кольца;
- указатель начала кольца, который хранит константу N – число просмотров строки, и адрес первого элемента строки;
- звенья связи элементов, содержащие адрес последующего элемента и адрес значения элемента, звено связи последнего элемента вместо признака конца списка содержит адрес указателя начала кольца.
При каждом просмотре кольца значение N уменьшается на единицу и проверяется условие N=0. Если N≠0,просмотр продолжается; при N=0 просмотр заканчивается. Двунаправленная кольцевая строка отличается от однонаправленной тем, что вместо указателя начала кольца вводятся два указателя со своими константами – это указатель начала прямого направления и указатель начала обратного направления со своими константами чисел просмотра
N1 и N2. Кроме того, звенья связи содержат адреса предыдущего и последующего элементов.
3.3 Древовидные (иерархические) структуры данных
Элементы древовидных структур данных (ДСД) располагаются на различных уровнях и соединяются с помощью адресов связи. ДСД соответствует графу типа «дерево» и представляется набором элементов, распределённых
по уровням иерархии следующим образом:
- На первом уровне расположен только один элемент, который называется корнем дерева;
- к любому элементу k-го уровня ведёт только один адрес связи;
- к любому элементу k-го уровня адрес связи идёт только от элемента(k-1)-го уровня.
Количество уровней в ДСД называют рангом. Элементы дерева, которые адресуются от общего элемента (k-1)-го уровня, образуют группу. Максимальное число элементов в группе называется порядком дерева. Деревья с порядком больше двух принято называть общими ДСД, а с порядком 2 − двоичными, или бинарными деревьями. Дерево порядка 1 – строчная структура.
В зависимости от количества элементов в группе некоторой вершины различают три типа вершин. Если n – порядок дерева, то вершины из n элементов называются полными, вершины, не имеющие группы – концевыми (листьями), а остальные неполными.
Для ДСД можно определить её двунаправленный и кольцевоё варианты. Если в однонаправленном варианте некоторая вершина А имеет адрес связи на вершину В, то в двунаправленном дереве дополнительно появится адрес связи от В к А. Если все концевые вершины дерева имеют адрес связи на вершину-корень, то ДСД называется кольцевой.
Наиболее распространённым видом ДСД являются бинарные деревья, в которых каждая вершина k-го уровня содержит два адреса (правый и левый) связи на вершины (k+1)-го уровня и один (обратный) – на вершину (k-1)-го уровня. Множество вершин, соединённых с данной вершиной через левый адрес связи, образует левую ветвь этой вершины. Аналогично определяется правая ветвь.
В случае, когда элементы дерева являются записями, наиболее распространённым условием организации бинарных деревьев является упорядоченность. Записям соответствуют ключи с числовыми значениями. Каждый элемент в упорядоченном бинарном дереве (УБД) имеет на своей левой ветви элементы с меньшим, чем у него, значением ключа, а на правой ветви — элементы с большим или равным значением ключа.
Имеются специальные разновидности бинарных деревьев, у которых размах расстояния Д от корня дерева до концевых вершин сравнительно невелик: подравненные и выровненные (в частном случае – симметричные).
Алгоритмы формирования таких деревьев более сложные, чем общий алгоритм формирования УБД.
Для общих ДСД часто используется разновидность: В-деревья (сбалансированные деревья) со специальным алгоритмом их формирования. В алгоритме формирования УБД дерево растёт вниз и его корень не меняется, а в алгоритме формирования В-дерева оно растёт вверх и его корень может меняться.
3.4 Сетевые структуры данных
Сетевые структуры данных представляют собой расширение дерева за счёт новых адресов связи на множестве элементов.
3.5 Табличные структуры данных
Табличная структура данных – структура, в которой адрес данного однозначно определяется двумя числами – номером стоки и номером столбца, на пересечении которых находится ячейка с искомым элементом. Табличные структуру предназначены для хранения информации о ключевых атрибутах заданного набора элементов, являющихся записями. Обычно это делают с выделением в памяти трёх областей:
- вектора описания записей;
- вектора описания ключей;
- матрицы значений ключей.
Отсутствие некоторых ключевых атрибутов приводит к незаполненным позициям в матрице значений ключей. Чтобы устранить их, используются специальные способы уплотнения (с помощью логической шкалы или индексных пар).
Таким образом, выделяются уплотнённые и неуплотнённые табличные структуры.
Гибридные структуры данных содержат фрагменты двух различных структур данных. Например, небольшие по объёму последовательные структуры данных соединяются между собой с помощью адресов связи в строчную структуру. Гибридные структуры данных различаются в зависимости от того, какие структуры данных используются при их формировании.
В различных процедурах работы с данными выгодно использование наиболее эффективных для решаемых задач структур. При размещении элементов массивов или записей в памяти обычно используются ПСД, при организации индексных файлов в методах доступа к данным – ДСД или табличные структуры, для организации скоростных буферов обмена – очереди, и так далее.
Заключение
Структура данных – это организационная схема записи или массива, в соответствии с которой упорядочены данные, с тем, чтобы их можно интерпретировать и выполнять над ними определённые операции. Это исполнитель, который организует работу с данными, включая их хранение, добавление и удаление, модификацию, поиск. Структура данных поддерживает определённый порядок доступа к ним. Понятие структуры данных можно определить, как совокупность внешних связей между элементами данных, которые на принятом уровне рассмотрения можно считать неделимыми, элементарными. Существуют следующие основные типы структур данных: списковые, древовидные или иерархические, сетевые, табличные.
сортировка
Несмотря на удобства, у простых структур данных есть и недостаток — их трудно обновлять. Пример: переводим студента из одной группы в другую, изменения надо вносить сразу в два журнала посещаемости; при этом в обоих журналах будет нарушена списочная структура. Если переведенного студента вписать в конец списка группы, нарушится упорядочение по алфавиту, а если его вписать в соответствии с алфавитом, то изменятся порядковые номера всех студентов, которые следуют за ним.
Таким образом, при добавлении произвольного элемента в упорядоченную структуру списка может происходить изменение адресных данных у других элементов , в системах, выполняющих автоматическую обработку данных, нужны специальные методы для решения этой проблемы. Древовидные (иерархические) структуры данных по форме сложнее, чем списковые структуры данных и табличные, но они не создают проблем с обновлением данных. Их легко развивать путем создания новых уровней.
индексации
Адресные данные,
Мы рассмотрели вопрос о важности структур данных и о том, как они влияют на эффективность алгоритмов. Выбор правильного представления данных служит ключом к удачному программированию и может в большей степени сказываться на производительности программы, чем детали используемого алгоритма.
Стоит добавить, что совокупность структур данных и операций их обработки составляет модель данных, которая является ядром любой базы данных и представляет собой множество структур данных, ограничений целостности и операций манипулирования данными. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними. База данных основывается на использовании иерархической, сетевой или реляционной модели, на комбинации этих моделей или на некотором их подмножестве.
Практическая часть
1. Общая характеристика задачи
Рассмотрим следующую задачу:
В бухгалтерии ООО «Снежок» производится расчет отчислений по каждому сотруднику предприятия:
- в федеральный бюджет;
- фонды обязательного медицинского страхования (ФФОМС – федеральный, ТФОМС – территориальный);
- фонд социального страхования (ФСС).
Процентные ставки отчислений приведены на рис. 6.1 . Данные для расчета отчислений в фонды по каждому сотруднику приведены на рис. 6.2 .
- Построить таблицы по приведённым ниже данным.
- Выполнить расчёт размеров отчислений с заработной платы по каждому сотруднику предприятия, данные расчета занести в таблицу (рис.6.2 ).
- Организовать межтабличные связи для автоматического формирования ведомости расчета ЕСН (единого социального налога ) по предприятию.
- Сформировать и заполнить ведомость расчета ЕСН (рис 6.3 ).
- Результаты расчета ЕСН по каждому сотруднику за текущий месяц представить в графическом виде.
СТАВКИ ЕСН
|
Фонд, В который производится отчисление |
Ставка, % |
|
ТФОМС |
2,00 |
|
Федеральный бюджет |
20,00 |
|
ФСС |
3,20 |
|
ФФОМС |
0,80 |
|
ИТОГО |
26,00 |
Рис. 6.1. Процентные ставки отчислений
|
Табельный номер |
ФИО сотрудника |
Начислено за Месяц, руб. |
Федеральный Бюджет, руб. |
ФСС, руб. |
ФФОМС, руб. |
ТФОМС, руб. |
Итого, руб. |
|
001 |
Иванов И.И. |
15 600,00 |
|||||
|
002 |
Сидоров А.А |
12 300,00 |
|||||
|
003 |
Матвеев К.К. |
9 560,00 |
|||||
|
004 |
Сорокин М.М. |
4 620,00 |
|||||
|
005 |
Петров С.С. |
7 280,00 |
Рис. 6.2. Данные для расчета ЕСН за текущий месяц по каждому сотруднику
|
ООО «Снежок»
ВЕДОМОСТЬ РАСЧЕТА ЕСН
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||
Рис. 6.3. Ведомость расчета ЕСН
2. Описание алгоритма решения задачи смотрте в файле
Список использованной литературы
[Электронный ресурс]//URL: https://liarte.ru/kursovaya/strukturyi-dannyih/
- Гуда А. Н., Бутакова М. А., Нечитайло Н. М., Чернов А.В. Информатика. Общий курс: Учебник / Под ред. академика РАН В. И. Колесникова. – М.: Издательско-торговая корпорация «Дашков и К»; Ростов н/Д: Наука-Пресс, 2007г. – 400 с.
- «Информатика. Терминологический словарь». Всероссийский НИИ комплексной информации по стандартизации и качеству; Москва, 2005г. – 350 с.
- «Информатика, общий курс» под ред. Колесникова В.И. Наука-Пресс. Москва, 2007г. – 315 с.
- Каймин В. А. Информатика: Учебник. — М.: ИНФРА-М, 2000г. — 232 с.
- Когаловский М.Р. «Энциклопедия технологий баз данных» Финансы и статистика; Москва, 2004г. – 195 с.
- Модели и структуры данных В. Д. Далека, А. С. Деревянко, О. Г. Кравец, Л. Е. Тимановская. Учебное пособие. Харьков: ХГПУ, 2000г. — 241с.
- Организация и обработка структур данных в вычислительных систем: Учебное пособие для вузов. Костин А.Е., Шаньгин В.Ф. 1987г. — 248 с.
- Соболь Б.В., Галин А.Б., Панов Ю.В., Рашидова Е.В., Садовой Н.Н. «Информатика»; Ростов н/Д: Феникс, 2005г. – 145 с.
- Советов Б. Я. Информационные технологии. Учебник для студентов вузов. 2006г. — 263 с.
- Уоллес Вонг. Основы программирования для «чайников». ДИАЛЕКТИКА. Москва – Санкт-Петербург – Киев. 2001г. – 335 с.
Публикации в сети Интернет
- Савчук В.Л. Виды форм представления информации.- http://www.ie.tusur.ru/books/COI/page_03.htm 13.03.2010г.
не сложно
Важно! Все представленные Курсовые работы для бесплатного скачивания предназначены для составления плана или основы собственных научных трудов.
Друзья! У вас есть уникальная возможность помочь таким же студентам как и вы! Если наш сайт помог вам найти нужную работу, то вы, безусловно, понимаете как добавленная вами работа может облегчить труд другим.
Если Курсовая работа, по Вашему мнению, плохого качества, или эту работу Вы уже встречали, об этом нам.