Появление компьютеров изменило весь мир. Сейчас этот продукт уже ни для кого не является эксклюзивным, более, можно сказать, что даже входит в список «техники первой необходимости». Естественно и вполне логично задаться вопросом: «Почему?»
Как известно уже давно, компьютеры были созданы для решения вычислительных задач, однако, с ними редко сталкивается современный среднестатистический пользователь, поэтому со временем они нашли более практическое применение, т.е. все чаще стали использоваться в повседневной жизни для построения систем обработки документов, а точнее, содержащейся в них информации. В качестве примера можно привести систему учета отработанного времени работниками предприятия и расчета заработной платы, систему учета продукции на складе, систему учета книг в библиотеке и т.д. Все вышеперечисленные системы имеют следующие особенности:
1. для обеспечения их работы нужны сравнительно низкие вычислительные мощности
2. данные, которые они используют, имеют сложную структуру, необходимы средства сохранения данных между последовательными запусками системы.
Другими словами, информационная система требует создания в памяти ЭВМ динамически обновляемой модели внешнего мира с использованием единого хранилища — базы данных. Словосочетание «динамически обновляемая» означает, что соответствие базы данных текущему состоянию предметной области обеспечивается не периодически, а в режиме реального времени. При этом одни и те же данные могут быть по-разному представлены в соответствии с потребностями различных групп пользователей.
Во время поиска информации по данной теме было обнаружено, что точного определения базы данных (хотя это далеко не философское понятие) не существует.
Базой данных, База данных(БД)
Было выделено несколько важных признаков Базы Данных: хранение и обработка в вычислительной системе, структурность (системность) организации.
Таким образом, всем студентам СПбГУЭФ как экономистам в дальнейшем постоянно придётся работать с такими системами, поэтому возникла необходимость более подробного их изучения.
Классификация Баз Данных
Существует огромное количество разновидностей баз данных, отличающихся по различным критериям (например, в «Энциклопедии технологий баз данных» М.Р. Когаловского определяются свыше 50 видов БД).
По модели данных:
- Иерархические
- Сетевые
- Реляционные
- Многомерные
- Объектные
- Объектно-ориентированные
- Объектно-реляционные
По технологии хранения:
Автоматизированная система обработки информации и управления (АСОИУ)
... в сфере коммерческого и технического учета. Автоматизированная система обработки информации и управления (АСОИУ) Основа электроэнергетики - объединенная энергетическая система, которая осуществляет технологический процесс производства ... глобальные сети. В подсистеме информационного обеспечения - это ведение баз данных под управлением СУБД. Интеграция математического обеспечения проявляется, прежде ...
- БД во вторичной памяти (традиционные)
- БД в оперативной памяти (in-memory databases)
- БД в третичной памяти (tertiary databases)
По содержимому:
- Географические
- Исторические
- Научные
- Мультимедийные
и т.д.
По степени распределённости:
- Централизованные (сосредоточенные)
- Распределённые
Отдельное место в теории и практике занимают пространственные (spatial), временные, или темпоральные (temporal) и пространственно-временные (spatial-temporal) БД.
Очень Большой Базе Данных.
Очень большая база данных (Very Large Database, VLDB) — это база данных, которая содержит чрезвычайно большое количество записей или занимает чрезвычайно большой объём на устройстве физического хранения. Термин подразумевает максимально возможные объёмы БД, которые определяются последними достижениями в технологиях физического хранения данных и в технологиях программного оперирования данными.
Конкретное определение понятия «чрезвычайно большой объём» меняется во времени; в настоящее время считается, что это объём, измеряемый по меньшей мере терабайтами.
Сверхбольшие базы и склады данных требуют особых подходов к логическому и системно-техническому проектированию, обычно выполняемому в рамках самостоятельного проекта, суть которого в том, чтобы найти такое системотехническое решение, которое попросту позволило бы хоть как-то работать с такими большими объемами. Такое решение возможно при наличии трех условий: специального решения для дисковой подсистемы, специальных версий операционной среды и специальных механизмов обращения СУБД к данным. Исследования в области хранения и обработки VLDB всегда находятся на острие теории и практики баз данных. В частности, с 1975 года проходит ежегодная конференция International Conference on Very Large Data Bases (Международная конференция по очень большим базам данных).
Большинство исследований проводится под эгидой некоммерческой организации VLDB Endowment («Вклад в VLDB»), которая обеспечивает продвижение научных работ и обмен информацией в области БД и смежных областях.
Основные типы данных
Для того чтобы разобраться с организацией Базы Данных (БД), надо разобраться, что собой представляют сами данные и какие они бывают.
Данные, хранящиеся в памяти ЭВМ, — это совокупность нулей и единиц (битов).
Какой смысл заключен в данных, какими символами они выражены — буквенными или цифровыми, что означает то или иное число — все это определяется программой обработки. Все данные необходимые для решения практических задач подразделяются на несколько типов, причем понятие тип связывается не только с представлением данных в адресном пространстве, но и со способом их обработки.
Любые данные могут быть отнесены к одному из двух типов: основному (простому), форма представления которого определяется архитектурой ЭВМ, или сложному, конструируемому пользователем для решения конкретных задач.
структуры (сложные типы) данных.
Структуры баз данных
Массив (функция с конечной областью определения) — простая совокупность элементов данных одного типа, средство оперирования группой данных одного типа. Отдельный элемент массива задается индексом. Массив может быть одномерным, двумерным и т.д. Разновидностями одномерных массивов переменной длины являются структуры типа кольцо, стек, очередь и двухсторонняя очередь.
Моей курсовой «Основные структуры данных»
... структурированные данные. Рассматриваются такие понятия, как «тип данных», «структура данных», «модель данных» и «база данных». В основной части работы приводится классификация структур данных, обширная информация о физическом и логическом представлении структур данных всех классов памяти ЭВМ: ...
Запись (декартово произведение) — совокупность элементов данных разного типа. В простейшем случае запись содержит постоянное количество элементов, которые называют полями. Совокупность записей одинаковой структуры называется файлом. (Файлом называют также набор данных во внешней памяти, например, на магнитном диске).
Для того, чтобы иметь возможность извлекать из файла отдельные записи, каждой записи присваивают уникальное имя или номер, которое служит ее идентификатором и располагается в отдельном поле. Этот идентификатор называют ключом.
Такие структуры данных как массив или запись занимают в памяти ЭВМ постоянный объем, поэтому их называют статическими структурами. К статическим структурам относится также множество.
динамические структуры
Важной структурой, для размещения элементов которой требуется нелинейное адресное пространство является дерево. Существует большое количество структур данных, которые могут быть представлены как деревья. Это, например, классификационные, иерархические, рекурсивные и др. структуры.
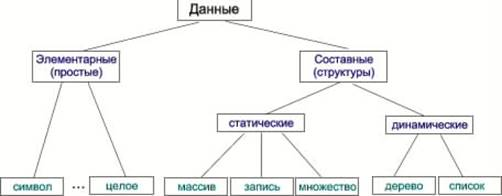
Классификация типов данных
Обобщенные структуры или модели данных
Выше я рассмотрела несколько типов структур, являющихся совокупностями элементов данных: массив, дерево, запись. Более сложный тип данных может включать эти структуры в качестве элементов. Например, элементами записи может быть массив, стек, дерево и т.д.
Существует большое разнообразие сложных типов данных, но исследования, проведенные на большом практическом материале, показали, что среди них можно выделить несколько наиболее общих. Обобщенные структуры называют также моделями данных, т.к. они отражают представление пользователя о данных реального мира.
Любая модель данных должна содержать три компонента:
структура данных
набор допустимых операций,
ограничения целостности
В процессе исторического развития в СУБД использовалось следующие модели представления данных:
иерархическая:
- сетевая: понятия главного и подчиненного несколько расширены;
- любой объект может быть и главным и подчиненным;
- означает, что каждый объект может участвовать в любом числе взаимосвязей.
реляционная:
В настоящее время наибольшую популярность приобрели реляционные модели данных, т.к их применение по ряду причин было выбрано программистами-разработчиками наиболее удобным. Как выяснилось, практически все СУБД сейчас ориентированы именно на такое представление данных. Реляционная модель была предложена в 1970-х гг. Тедом Коддом, работавшим тогда в IВM.
Реляционную модель можно представить как особый метод рассмотрения данных, содержащий и собственно данные (в виде таблиц), и способы работы и манипуляции с ними (в виде связей).
В последнее время все большее значение приобретает объектно-ориентированный подход к представлению данных.
Физическая организация баз данных
Физическая организация данных определяет собой способ непосредственного размещения данных на машинном носителе. В современных прикладных программных средствах этот уровень организации обеспечивается автоматически без вмешательства пользователя. Пользователь, как правило, оперирует в прикладных программах и универсальных программных средствах представлениями о логической организации данных.
Организация данных во внешней памяти
блоков (страниц) данных.
Обмен данными между внешней и оперативной памятью выполняется блоками,
В качестве адресов записей файла во внешней памяти используют: машинный адрес, относительный адрес, ключ записи. В качестве относительного адреса записи файла используют ее номер по порядку (внутрисистемный номер) в файле, либо комбинацию номера блока и относительного адреса в блоке, либо номер блока и значение ключа. Во многих системах при вводе записи ей присваивается уникальный системный идентификатор — ключ базы данных. Ключ БД не следует отождествлять с ключом записи. Последний задается и используется пользователем (прикладной программой).
виртуальными (например, возраст).
Каждая физическая запись, соответствующая логической, состоит обычно из двух частей — служебной и информационной. Поля служебной (прозрачной) части используются СУБД для идентификации записи, задания ее типа, хранения признака логического удаления, для кодирования значений элементов, для установления структурных связей между записями. Никакие пользовательские программы не имеют доступа к служебной части записи.
Записи обычно размещаются в блоках плотно, без промежутков, последовательно одна за другой. В блоке часть памяти отводится также для служебной информации о блоке: относительные адреса свободных участков памяти, указатели на следующий блок и т.д.
Обычно блоки заполняются не полностью. Оставшаяся часть блока остается некоторое время незаполненной (зарезервированной).
В дальнейшем эта область заполняется при увеличении (расширении) записей, хранящихся в блоке, или при поступлении в систему новых записей, которые в соответствии со значениями их ключей (или по другим условиям) надо поместить в одном блоке с уже хранящимися записями. По истечении некоторого времени блок заполняется полностью. Для хранения новых поступающих данных, которые должны были бы попасть в этот блок, выделяется дополнительный блок памяти в области переполнения. Записи, которые должны были размещаться в одном блоке, связываются специальными указателями в одну цепь. Файл периодически реорганизуется: при необходимости файлу добавляется требуемое количество блоков в основной внешней памяти и выполняется требуемая перекомпоновка записей, с целью освобождения области переполнения внешней памяти.
Методы доступа к данным
Как уже неоднократно упоминалось, простой пользователь не имеет дело с самой базой данных, а работает в прикладных программах. Следовательно появляется задача организации доступа к БД.
выборка, изменение, включение и исключение данных
В задачах поиска предполагается, что все данные хранятся в памяти с определенной идентификацией и, говоря о доступе, имеют в виду прежде всего доступ к данным (называемым ключами), однозначно идентифицирующим связанные с ними совокупности данных.
Пусть нам необходимо организовать доступ к файлу, содержащему набор одинаковых записей, каждая из которых имеет уникальное значение ключевого поля. Самый простой способ поиска — последовательно просматривать каждую запись в файле до тех пор, пока не будет найдена та, значение ключа которой удовлетворяет критерию поиска. Очевидно, этот способ весьма неэффективен, поскольку записи в файле не упорядочены по значению ключевого поля. Сортировка записей в файле также неприменима, поскольку требует еще больших затрат времени и должна выполняться после каждого добавления записи. Поэтому, поступают следующим образом — ключи вместе с указателями на соответствующие записи в файле копируют в другую структуру, которая позволяет быстро выполнять операции сортировки и поиска. При доступе к данным вначале в этой структуре находят соответствующее значение ключа, а затем по хранящемуся вместе с ним указателю получают запись из файла.
Существуют два класса методов, реализующих доступ к данным по ключу:
- методы поиска по дереву
- методы хеширования.
Методы поиска по дереву
Деревом называется конечное множество, состоящее из одного или более элементов, называемых узлами, таких, что:
- между узлами имеет место отношение типа «исходный-порожденный»;
- есть только один узел, не имеющий исходного. Он называется корнем;
- все узлы за исключением корня имеют только один исходный;
- каждый узел может иметь несколько порожденных;
- отношение «исходный-порожденный» действует только в одном направлении, т.е.
ни один потомок некоторого узла не может стать для него предком.
Узел с нулевой степенью называют листом или концевым узлом.
Если в дереве между порожденными узлами, имеющими общий исходный, считается существенным их порядок, то дерево называется упорядоченным. В задачах поиска почти всегда рассматриваются упорядоченные деревья.
Упорядоченное дерево, степень которого не больше 2 называется бинарным деревом. Бинарное дерево особенно часто используется при поиске в оперативной памяти. Алгоритм поиска: вначале аргумент поиска сравнивается с ключом, находящимся в корне. Если аргумент совпадает с ключом, поиск закончен, если же не совпадает, то в случае, когда аргумент оказвается меньше ключа, поиск продолжается в левом поддереве, а в случае когда больше ключа — в правом поддереве. Увеличив уровень на 1 повторяют сравнение, считая текущий узел корнем.
Пример: Пусть дан список студентов, содержащий их фамили и средний бал успеваемости (см. таблицу 1.1).
В качестве ключа используется фамилия студента. Предположим, что все записи имеют фиксированную длину, тогда в качестве указателя можно использовать номер записи. Смещение записи в файле в этом случае будет вычислятся как ([номер_записи] -1 ) * [длина_записи]. Пусть аргумент поиска «Петров». На рисунке 1.2 показаны одно из возможных для этого набора данных бинарных деревьев поиска и путь поиска.
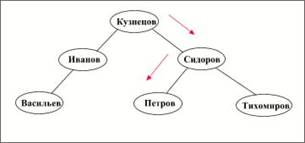
Рис. 1.2
Таблица 1.1
| студент | балл |
| Иванов | 3,4 |
| Васильев | 4,2 |
| Кузнецов | 3,5 |
| Петров | 3,2 |
| Сидоров | 4,6 |
| Тихомиров | 3,8 |
Заметим, что здесь используется следующее правило сравнения строковых переменных: считается, что значение символа соответствует его порядковому номеру в алфавите. Поэтому «И» меньше «К», а «К» меньше «С». Если текущие символы в сравниваемых строках совпадают, то сравниваются символы в следующих позициях.
Бинарные деревья особенно эффективны в случае когда множество ключей заранее неизвестно, либо когда это множество интенсивно изменяется. Очевидно, что при переменном множестве ключей лучше иметь сбалансированное дерево.
Бинарное дерево называют сбалансированным
При поиске данных во внешней памяти очень важной является проблема сокращения числа перемещений данных из внешней памяти в оперативную. Поэтому, в данном случае по сравнению с бинарными деревьями более выгодными окажутся сильно ветвящиеся деревья — т.к. их высота меньше, то при поиске потребуется меньше обращений к внешней памяти. Наибольшее применение в этом случае получили В-деревья (В — balanced) .
В-деревом порядка n
- Каждый узел, за исключением корня, содержит не менее n и не более 2n ключей.
- Корень содержит не менее одного и не более 2n ключей.
- Все листья расположены на одном уровне.
- Каждый нелистовой узел содержит два списка: упорядоченный по возрастанию значений список ключей и соответсвующий ему список указателей (для листовых узлов список указателей отсутствует).
Для такого дерева:
- сравнительно просто может быть организован последовательный доступ;
- все листья расположены на одном уровне;
- при добавлении и изменении ключей все изменения ограничиваются, как правило, одним узлом.
Следует отметить, что B- деревья наилучшим образом подходят только для организации доступа к достаточно простым (одномерным) структурам данных. Для доступа к более сложным структурам, таким, например, как пространственные (многомерные) данные в последнее время все чаще используют R-деревья.
R-дерево (R-Tree) это индексная структура для доступа к пространственным данным, предложенная А.Гуттманом (Калифорнийский университет, Беркли).
R-дерево допускает произвольное выполнение операций добавления, удаления и поиска данных без периодической переиндексации.
Хеширование
Этот метод используется тогда, когда все множество ключей заранее известно и на время обработки может быть размещено в оперативной памяти. В этом случае строится специальная функция, однозначно отображающая множество ключей на множество указателей, называемая хеш-функцией (от английского «to hash» — резать, измельчать).
Имея такую функцию можно вычислить адрес записи в файле по заданному ключу поиска. В общем случае ключевые данные, используемые для определения адреса записи организуются в виде таблицы, называемой хеш-таблицей.
Если множество ключей заранее неизвестно или очень велико, то от идеи однозначного вычисления адреса записи по ее ключу отказываются, а хеш-функцию рассматривают просто как функцию, рассеивающую множество ключей во множество адресов.
Для более продвинутого пользователя можно привести следующее определение:
Хеширование
Хеширование применяется для сравнения данных: если у двух массивов хеш-функции разные, массивы гарантированно различаются; если одинаковые — массивы, скорее всего, одинаковы. В общем случае однозначного соответствия между исходными данными и хеш-кодом нет в силу того, что количество значений хеш-функций меньше чем вариантов входного массива; существует множество массивов, дающих одинаковые хеш-коды — так называемые коллизии. Вероятность возникновения коллизий играет немаловажную роль в оценке качества хеш-функций.
Существует множество алгоритмов хеширования с различными характеристиками (разрядность, вычислительная сложность, криптостойкость и т. п.).
Выбор той или иной хеш-функции определяется спецификой решаемой задачи.
Бытовым аналогом хеширования в данном случае может служить помещение слов в словаре по алфавиту. Первая буква слова является его хеш-кодом, и при поиске мы просматриваем не весь словарь, а только нужную букву.
Недостатки методов хеширования:, Заключение
По мере написания данной работы автором было выяснено несколько важных моментов:
1. База Данных — это одно из ключевых понятий, связанных с программированием и компьютерами в целом. Ведь, если рассуждать сугубо с точки зрения обычного пользователя, который не является ни математиком, ни физиком, главная функция компьютера как такового — хранение и предоставление в нужный момент определенных данных.
2. БД имеют огромное прикладное значения, широко применяются в производстве и повседневной жизни, т.к существенно облегчают работу по поиску информации, которая без существования подобных структур превратила бы простую задачу, возникающую постоянно в ходе какой-либо деятельности, в практически нерешаемую.
Естественно, что такое широкое распространение БД требует их и СУБД постоянного совершенствования и развития.
Список литературы:
[Электронный ресурс]//URL: https://liarte.ru/referat/fizicheskaya-organizatsiya-dannyih/
1. К. Дж. Дейт Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: «Вильямс», 2006. — 1328 с. — ISBN 0-321-19784-4
2. Кузнецов Сергей Дмитриевич Основы баз данных. — 1-е изд. — М.: «Интернет-университет информационных технологий — ИНТУИТ.ру», 2005. — 488 с. — ISBN 5-9556-00028-0
3. Когаловский М.Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002. — 800 с. — ISBN 5-279-02276-4
4.
5. http://www.mstu.edu.ru/education/materials/zelenkov/toc.html