Для чего нужны базы данных.
Компьютеры были созданы для решения вычислительных задач, однако со временем они все чаще стали использоваться для построения систем обработки документов, а точнее, содержащейся в них информации. Такие системы обычно и называют информационными. В качестве примера можно привести систему учета отработанного времени работниками предприятия и расчета заработной платы, систему учета продукции на складе, систему учета книг в библиотеке и т.д. Все вышеперечисленные системы имеют следующие особенности:
для обеспечения их работы нужны сравнительно низкие вычислительные мощности
данные, которые они используют, имеют сложную структуру
необходимы средства сохранения данных между последовательными запусками системы
Другими словами, информационная система требует создания в памяти ЭВМ динамически обновляемой модели внешнего мира с использованием единого хранилища — базы данных.
Словосочетание «динамически обновляемая» означает, что соответствие базы данных текущему состоянию предметной области обеспечивается не периодически, а в режиме реального времени. При этом одни и те же данные могут быть по-разному представлены в соответствии с потребностями различных групп пользователей.
Основная цель проектирования баз данных — это сокращение избыточности хранимых данных, а следовательно, экономия объема используемой памяти, уменьшение затрат на многократные операции обновления избыточных копий и устранение возможности возникновения противоречий из-за хранения в разных местах сведений об одном и том же объекте.
Цель моей курсовой заключается в анализе создания и администрирование баз данных.
Объектом исследования выступают базы данных.
Предмет исследования: система управления базой данных (СУБД).
1 Понятие базы данных
Под базой данных (БД) понимают хранилище структурированных данных, при этом данные должны быть непротиворечивы, минимально избыточны и целостны.
База данных — это поименованная совокупность структурированных данных, относящихся к определенной предметной области.
Жизненный цикл любого программного продукта, в том числе и системы управления базой данных, состоит из стадий проектирования, реализации и эксплуатации.
Базы данных и системы управления базами данных
... В отличие от современных систем управления, которые могут применяться для самых различных баз данных, подавляющее большинство ранее разработанных СУБД были тесно связаны с пользовательской базой для того, чтобы ...
Естественно, наиболее значительным фактором в жизненном цикле приложения, работающего с базой данных, является стадия проектирования. От того, насколько тщательно продумана структура базы, насколько четко определены связи между ее элементами, зависит производительность системы и ее информационная насыщенность, а значит — и время ее жизни.
Обычно БД создается для хранения и доступа к данным, содержащим сведения о некоторой предметной области, то есть некоторой области человеческой деятельности или области реального мира. Всякая БД должна представлять собой систему данных о предметной области. БД, относящиеся к одной и той же предметной области, в различных случаях содержат более или менее детализированную информацию о ней, причем таким способом, который заведомо исключает ненужную избыточность. В хорошо спроектированной базе данных избыточность данных исключается, и вероятность сохранения противоречивых данных минимизируется. Таким образом, создание баз данных преследует две основные цели: понизить избыточность данных и повысить их надежность.
Хорошо спроектированная база данных:
- Удовлетворяет всем требованиям пользователей к содержимому базы данных. Перед проектированием базы необходимо провести обширные исследования требований пользователей к функционированию базы данных.
— Гарантирует непротиворечивость и целостность данных. При проектировании таблиц нужно определить их атрибуты и некоторые правила, ограничивающие возможность ввода пользователем неверных значений. Для верификации данных перед непосредственной записью их в таблицу база данных должна осуществлять вызов правил модели данных и тем самым гарантировать сохранение целостности информации.
- Обеспечивает естественное, легкое для восприятия структурирование информации. Качественное построение базы позволяет делать запросы к базе более «прозрачными» и легкими для понимания; следовательно, снижается вероятность внесения некорректных данных и улучшается качество сопровождения базы.
— Удовлетворяет требованиям пользователей к производительности базы данных. При больших объемах информации вопросы сохранения производительности начинают играть главную роль, сразу «высвечивая» все недочеты этапа проектирования.
1.1 Система управления базами данных
Система управления базами данных — это комплекс программных и языковых средств, необходимых для создания баз данных, поддержания их в актуальном состоянии и организации поиска в них необходимой информации.
Таким образом, система управления базой данных (СУБД) — важнейший компонент информационной системы. Для создания и управления информационной системой СУБД необходима в той же степени, как для разработки программы на алгоритмическом языке необходим транслятор. Основные функции СУБД:
- управление данными во внешней памяти (на дисках);
- управление данными в оперативной памяти;
- журнализация изменениий и восстановление базы данных после сбоев;
- поддержание языков БД (язык определения данных, язык манипулирования данными).
Обычно современная СУБД содержит следующие компоненты (см. рис.):
ядро, которое отвечает за управление данными во внешней и оперативной памяти и журнализацию,
процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода,
База данных. База знаний. Банк данных
... представления знаний, при помощи которых строятся экспертные системы. 1.1 Базы данных и системы управления базами данных База данных - организованная в соответствии с определёнными правилами и поддерживаемая в памяти компьютера совокупность данных, характеризующая актуальное состояние некоторой предметной области и ...
подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД
а также сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
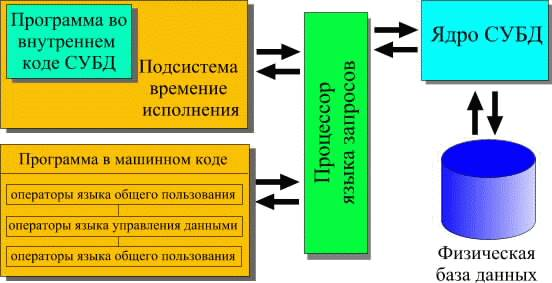
Рис 1 СУБД.
Создание первых баз данных и СУБД стало возможно лишь с появлением достаточно дешевых и производительных устройств внешней памяти, какими стали жесткие диски (винчестеры), появившиеся во второй половине 60-х годов. В 70-е годы шла интенсивная разработка теоретических вопросов построения баз данных. В результате в начале 80-х годов на рынке появились мощные инструментальные средства проектирования и построения информациоонных систем. Однако, развитие информационных технологий в 90-х привело к появлению новых, более широких требований к обработке и представлению данных. Таким образом, теория баз данных, хотя и располагает впечатляющими достижениями, еще далека от завершения.
На настоящий момент существует множество различных СУБД. Наиболее широкую известность получили такие как Dbase, Clipper, FoxPro, Paradox, Microsoft Access.
1.2 Типы СУБД
По технологии обработки данных базы данных подразделяются на централизованные и распределенные.
Централизованная база данных хранится в памяти одной вычислительной системы. Если эта вычислительная система является компонентом сети ЭВМ, возможен распределенный доступ к такой базе. Такой способ использования баз данных часто применяют в локальных сетях ПК.
Распределенная база данных состоит из нескольких, возможно пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети. Работа с такой базой осуществляется с помощью системы управления распределенной базой данных (СУРБД).
По способу доступа к данным базы данных разделяются на базы данных с локальным доступом и базы данных с удаленным доступом.
Системы централизованных баз данных с сетевым доступом предполагают различные архитектуры подобных систем;
- файл-сервер;
- клиент-сервер.
Файл-сервер. Архитектура систем БД с сетевым доступом предполагает выделение одной из машин сети в качестве центрального сервера файлов. На такой машине хранится совместно используемая централизованная БД. Все другие машины сети выполняют функции рабочих станций, с помощью которых поддерживается доступ пользовательской системы к централизованной базе данных. Файлы базы данных в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится обработка. При большой интенсивности доступа к одним и тем же данным производительность информационной системы падает. Пользователи могут создавать также на рабочих станциях локальные БД, которые используются ими монопольно.
Клиент-сервер. В этой концепции подразумевается, что помимо хранения централизованной базы данных центральная машина (сервер базы данных) должна обеспечивать выполнение основного объема обработки данных. Запрос на данные, выдаваемый клиентом (рабочей станцией), порождает поиск и извлечение данных на сервере. Извлеченные данные, но не файлы транспортируются по сети от сервера к клиенту. Спецификой архитектуры клиент-сервер является использование языка запросов SQL.
База данных. Понятие базы данных. Виды баз данных. Объекты для ...
... для хранения данных. Для разработки программ, систем программ, работающих с базами данных, используются специальные средства – системы управления базами данных (СУБД). СУБД включает, ... база данных, разные части которой хранятся на различных компьютерах, объединённых в сеть; 4.Централизованная – база данных, хранящихся на одном компьютере; 5.Реляционная – база данных с табличной организацией данных. ...
По степени универсальности различают два класса СУБД:
- системы общего назначения;
- специализированные системы.
СУБД общего назначения не ориентированы на какую-либо предметную область или на информационные потребности какой-либо группы пользователей. Каждая система такого рода реализуется как программный продукт, способный функционировать на некоторой модели ЭВМ в определенной операционной системе и поставляется многим пользователям как коммерческое изделие. Такие СУБД обладают средствами настройки на работу с конкретной базой данных. СУБД общего назначения — это сложные программные комплексы, предназначенные для выполнения всей совокупности функций, связанных с созданием и эксплуатацией базы данных информационной системы.
Использование СУБД общего назначения в качестве инструментального средства для создания автоматизированных информационных систем, основанных на технологии баз данных, позволяет существенно сокращать сроки разработки и экономить трудовые ресурсы. Этим СУБД присущи развитые функциональные возможности и определенная функциональная избыточность.
Специализированные СУБД создаются в редких случаях при невозможности или нецелесообразности использования СУБД общего назначения.
2 Модели данных
Ядром любой базы данных является модель данных. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними.
Модель данных — это совокупность структур данных и операций их обработки. Рассмотрим три основных типа моделей данных: иерархическую, сетевую и реляционную.
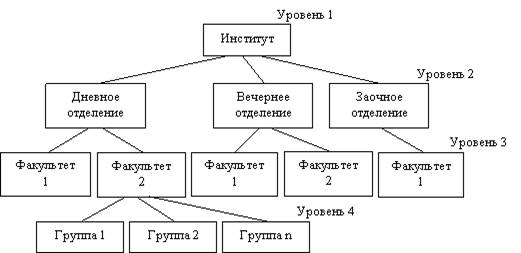
Рис 2 Иерархическая модель
Иерархическая модель представляет собой совокупность элементов, расположенных в порядке их подчинения от общего к частному и образующих перевернутое по структуре дерево (граф).
К основным понятиям иерархической структуры относятся уровень, узел и связь. Узел — это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину, не подчиненную никакой другой вершине и находящуюся на самом верхнем — первом уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т. д. уровнях. Количество деревьев в базе данных определяется числом корневых записей. К каждой записи базы данных существует только один иерархический путь от корневой записи.
Рис 3 сетевая структура
В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом.
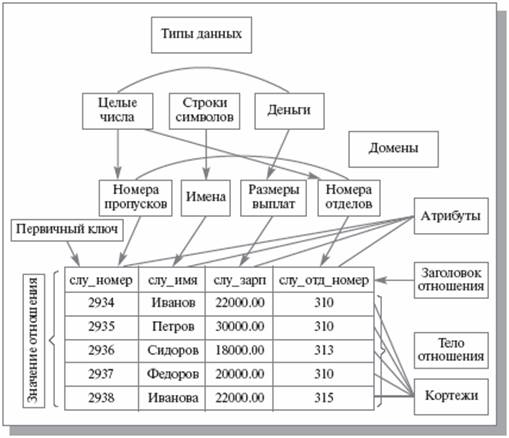
Рис 4 Реляционная модель
Реляционная модель данных объекты и связи между ними представляет в виде таблиц, при этом связи тоже рассматриваются как объекты. Все строки, составляющие таблицу в реляционной базе данных, должны иметь первичный ключ. Все современные средства СУБД поддерживают реляционную модель данных.
Создание базы данных «Музыкальные записи»
... записей быстро развились к более мощной модели записей, ориентированной на наборы. За руководство работой Data Base Task Group (DBTG), разработавшей стандартный язык описания данных и манипулирования данными, ... и предназначенной для использования несколькими пользователями. Система управления базами данных (СУБД) - специализированная программа (чаще комплекс программ), предназначенная для организации ...
Эта модель характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
1. Каждый элемент таблицы соответствует одному элементу данных.
2. Все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип и длину.
3. Каждый столбец имеет уникальное имя.
4. Одинаковые строки в таблице отсутствуют;
5. Порядок следования строк и столбцов может быть произвольным.
2.2 Информационные единицы баз данных
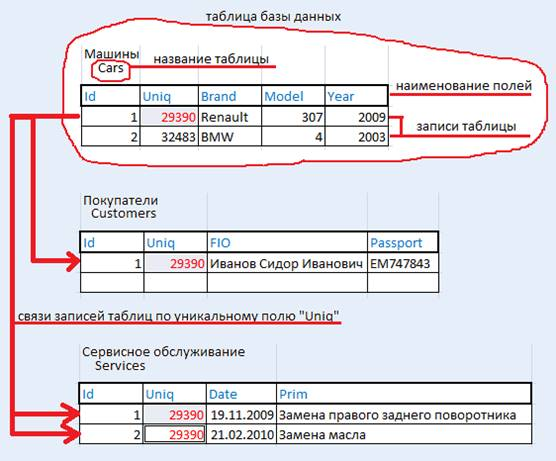
Рис 5 Таблица, Поле, Записи, Ключи
Объектами обработки СУБД являются следующие информационные единицы.
Поле — элементарная единица логической организации данных, которая соответствует неделимой единице информации — реквизиту.
Запись — совокупность логически связанных полей.
Экземпляр записи — отдельная реализация записи, содержащая конкретные значения ее полей.
Таблица — упорядоченная структура, состоящая из конечного набора однотипных записей.
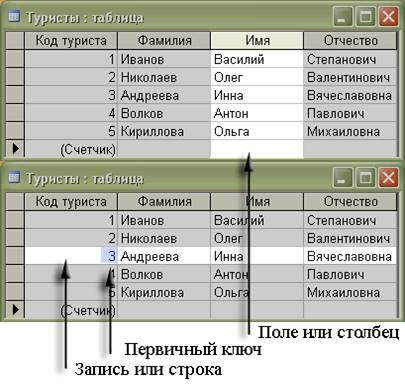
Рис 6 Таблица, Поле, столбец, Запись, строка, Первичный ключ
Первичный ключ — поле или группа полей, позволяющие однозначным образом определить каждую строку в таблице. Первичный ключ должен обладать двумя свойствами:
Однозначная идентификация записи: запись должна однозначно определяться значением ключа.
Отсутствие избыточности: никакое поле нельзя удалить из ключа, не нарушая при этом свойства однозначной идентификации.
Кроме первичного, могут использоваться так называемые простые (или вторичные) ключи таблицы. Простых ключей может быть множество. Они используются при упорядочивании (индексировании) таблиц.
В процессе разработки модели данных необходимо выделить информационные объекты, соответствующие требованиям нормализации данных, и определить связи между ними. Эта модель позволяет создать реляционную базу данных без дублирования, в которой обеспечивается однократный ввод данных при первоначальной загрузке и корректировках, а также целостность данных при внесении изменений.
При определении логической структуры реляционной базы данных на основе модели каждый информационный объект адекватно отображается реляционной таблицей, а связи между таблицами соответствуют связям между информационными объектами. Далее мы более подробно рассмотрим взаимосвязи между информационными объектами, т.е. таблицами.
2.3 Построение информационно-логической модели данных
Рис 7 представлена графическая форма информационно-логической модели
Проектирование и разработка реляционной базы данных для информационной ...
... и анализу информации. Целью данной курсовой работы является создание реляционной базы данных зоомагазина и разработка приложения для работы с данной базой. В ... базы данных необходимо определить совокупность отношений, составляющих базу данных. Эта совокупность отношений будет содержать всю информацию, которая должна храниться в базе данных. На основе полученной в первом пункте концептуальной модели ...
Информационно- логическая модель (ИЛМ) отображает данные предметной области в виде совокупности информационных объектов и связей между ними. Эта модель представляет данные, подлежащие хранению в базе данных.
Информационный объект — это описание некоторой сущности предметной области — реального объекта, процесса, явления или события. Информационный объект образуется совокупностью логически взаимосвязанных реквизитов, представляющих качественные и количественные характеристики сущности. Примерами информационных объектов могут быть: СТУДЕНТ, ПРЕПОДАВАТЕЛЬ, КАФЕДРА и т. п.
Информационные объекты могут быть выделены на основе описания предметной области путем определения функциональных зависимостей между реквизитами. Совокупность реквизитов информационного объекта должна отвечать требованиям нормализации.
Каждому информационному объекту нужно присвоить уникальное имя, например, СТУДЕНТ, ПРЕДМЕТ, ПРЕПОДАВАТЕЛЬ, КАФЕДРА.
Информационный объект имеет множество реализаций или экземпляров. Например, каждый экземпляр объекта СТУДЕНТ представляет конкретного студента. Экземпляр объекта образуется совокупностью конкретных значений реквизитов и должен однозначно определяться, т. е. идентифицироваться значением ключа информационного объекта, который состоит из одного или нескольких ключевых реквизитов. Таким образом, реквизит подразделяются на ключевые и описательные, которые являются функционально зависимыми от ключа.
Ключи
Легко заметить, что отношение является отражением некоторой сущности реального мира и с точки зрения обработки данных представляет собой таблицу. Поскольку в локальных базах данных каждая таблица размещается в отдельном файле, то с точки зрения размещения данных для локальных баз данных отношение можно отождествлять с файлом. Кортеж представляет собой строку в таблице, или, что то же самое, запись. Атрибут же является столбцом таблицы, или — полем в записи. Домен же представляется неким обобщенным типом, который может быть источником для типов полей в записи.
Таким образом, следующие тройки терминов являются эквивалентными:
- отношение, таблица, файл (для локальных баз данных);
- кортеж, строка, запись;
- атрибут, столбец, поле.
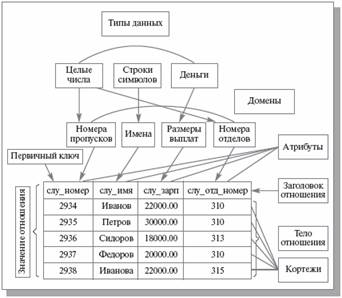
Рис 8 Кортеж, строка, запись, атрибут, столбец, поле
Реляционная база данных представляет собой совокупность отношений, содержащих всю необходимую информацию и объединенных различными связями.
Атрибут (или набор атрибутов), который может быть использован для однозначной идентификации конкретного кортежа (строки, записи), называется первичным ключом. Первичный ключ не должен иметь дополнительных атрибутов. Это значит, что если из первичного ключа исключить произвольный атрибут, оставшихся атрибутов будет недостаточно для однозначной идентификации отдельных кортежей. Для ускорения доступа по первичному ключу во всех системах управления базами данных (СУБД) имеется механизм, называемый индексированием. Грубо говоря, индекс представляет собой инвертированный древовидный список, указывающий на истинное местоположение записи для каждого первичного ключа. Естественно, в разных СУБД индексы реализованы по-разному (в локальных СУБД — как правило, в виде отдельных файлов), однако, принципы их организации одинаковы.
Реляционная модель данных в системах управления базами данных
... одно и то же значение в столбце Номер детали . Если таблица удовлетворяет этому требованию, она называется отношением (relation). Взаимосвязь таблиц является важнейшим элементом реляционной модели данных. Она поддерживается внешними ключами ...
Возможно индексирование отношения с использованием атрибутов, отличных от первичного ключа. Данный тип индекса называется вторичным индексом и применяется в целях уменьшения времени доступа при нахождении данных в отношении, а также для сортировки. Таким образом, если само отношение не упорядочено каким-либо образом и в нем могут присутствовать строки, оставшиеся после удаления некоторых кортежей, то индекс (для локальных СУБД — индексный файл), напротив, отсортирован.
2.4 Взаимосвязи данных
Основой любой базы данных являются таблицы. Таблица состоит из строк и столбцов и имеет уникальное имя в базе данных. База данных содержит множество таблиц, связь между которыми устанавливается с помощью совпадающих полей. В каждой из таблиц содержится информация о каких-либо объектах одного типа (группы).
Между таблицами в базе данных устанавливаются отношения. Имеются четыре типа отношений между таблицами: один-к-одному, один-ко-многим, много-к-одному, много-ко-многим.
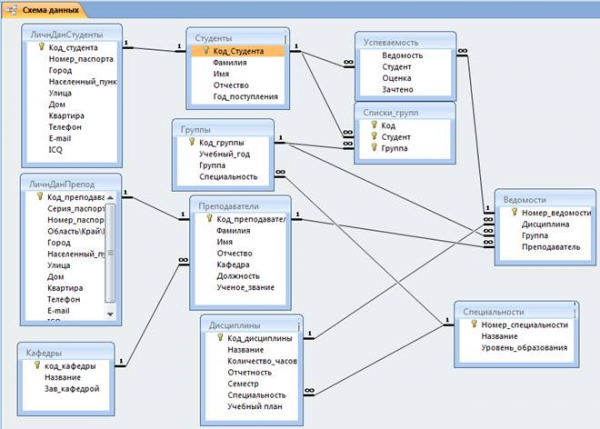
Рис 9 Взаимосвязи данных
Отношение один-к-одному означает, что каждая запись одной таблицы соответствует только одной записи в другой таблице. Например, если рассматривать таблицы, одна из которых содержит данные о сотрудниках предприятия, а вторая — профессиональные сведения, то можно сказать, что между этими таблицами существует отношение один-к-одному, поскольку для одного человека, информация о котором содержится в первой таблице, может существовать только одна запись, содержащая профессиональные сведения, во второй таблице.
Наиболее часто встречающимся типом отношений в базе данных является отношение один-ко-многим. В качестве иллюстрации данного типа отношения можно обратиться к таблицам, содержащим информацию о клиентах предприятия и сделанных ими заказах.
Отношение много-к-одному аналогично рассмотренному ранее типу один-ко-многим. Тип отношения между объектами зависит от вашей точки зрения. Например, если вы будете рассматривать отношение между сделанными заказами и клиентами, то получите отношение много-к-одному.
Отношение много-ко-многим возникает между двумя таблицами в тех случаях, когда: одна запись из первой таблицы может быть связана более чем с одной записью из второй таблицы;
- одна запись из второй таблицы может быть связана более чем с одной записью из первой таблицы.
3 Проектирование базы данных
Перед созданием базы данных необходимо располагать описанием выбранной предметной области, которое должно охватывать реальные объекты и процессы, определить все необходимые источники информации для удовлетворения предполагаемых запросов пользователя и определить потребности в обработке данных.
На основе такого описания на этапе проектирования базы данных определяется состав и структура данных предметной области, которые должны находиться в БД и обеспечивать выполнение необходимых запросов и задач пользователя. Структура данных предметной области может отображаться информационно-логической моделью. На основе этой модели легко создается реляционная база данных.
Библиографические базы данных ( ивные журналы ВИНИТИ, базы данных ...
... тома, номера, страниц), реферат, а также классификационные коды, слова из тезауруса и ключевые слова. Библиографическая база данных Article Sciences ) База данных статей из научной периодики. ... журналов на различных европейских языках. Статьи сопровождаются рефератами, объем которых иногда весьма внушителен. Библиографическая база данных British Library Direct Проект реализуется Британской ...
3.1 Этапы проектирования баз данных
При разработке БД можно выделить следующие этапы работы.
I этап. Постановка задачи.
На этом этапе формируется задание по созданию БД. В нем подробно описывается состав базы, назначение и цели ее создания, а также перечисляется, какие виды работ предполагается осуществлять в этой базе данных (отбор, дополнение, изменение данных, печать или вывод отчета и т. д).
II этап. Анализ объекта.
На этом этапе рассматривается, из каких объектов может состоять БД, каковы свойства этих объектов. После разбиения БД на отдельные объекты необходимо рассмотреть свойства каждого из этих объектов, или, другими словами, установить, какими параметрами описывается каждый объект. Все эти сведения можно располагать в виде отдельных записей и таблиц. Далее необходимо рассмотреть тип данных каждой отдельной единицы записи. Сведения о типах данных также следует занести в составляемую таблицу.
III этап. Синтез модели.
На этом этапе по проведенному выше анализу необходимо выбрать определенную модель БД. Далее рассматриваются достоинства и недостатки каждой модели и сопоставляются с требованиями и задачами создаваемой БД. После такого анализа выбирают ту модель, которая сможет максимально обеспечить реализацию поставленной задачи. После выбора модели необходимо нарисовать ее схему с указанием связей между таблицами или узлами.
IV этап. Выбор способов представления информации и программного инструментария.
После создания модели необходимо, в зависимости от выбранного программного продукта, определить форму представления информации.
В большинстве СУБД данные можно хранить в двух видах:
- с использованием форм;
- без использования форм.
Форма – это созданный пользователем графический интерфейс для ввода данных в базу.
V этап. Синтез компьютерной модели объекта.
В процессе создания компьютерной модели можно выделить некоторые стадии, типичные для любой СУБД.
Стадия 1. Запуск СУБД, создание нового файла базы данных или открытие созданной ранее базы.
Стадия 2. Создание исходной таблицы или таблиц.
Создавая исходную таблицу, необходимо указать имя и тип каждого поля. Имена полей не должны повторяться внутри одной таблицы. В процессе работы с БД можно дополнять таблицу новыми полями. Созданную таблицу необходимо сохранить, дав ей имя, уникальное в пределах создаваемой базы.
При проектировании таблиц, рекомендуется руководствоваться следующими основными принципами:
1. Информация в таблице не должна дублироваться. Не должно быть повторений и между таблицами. Когда определенная информация хранится только в одной таблице, то и изменять ее придется только в одном месте. Это делает работу более эффективной, а также исключает возможность несовпадения информации в разных таблицах. Например, в одной таблице должны содержаться адреса и телефоны клиентов.
2. Каждая таблица должна содержать информацию только на одну тему. Сведения на каждую тему обрабатываются намного легче, если они содержатся в независимых друг от друга таблицах. Например, адреса и заказы клиентов лучше хранить в разных таблицах, с тем, чтобы при удалении заказа информация о клиенте осталась в базе данных.
База данных гостиницы
... которой определить связи между таблицами базы данных. Ввести данные в таблицы базы данных. База данных должна содержать сведения о следующих объектах: Распределение номеров по ... появляется собственно сама база данных. База данных реализована на конкретной программно-аппаратной основе, и выбор этой основы позволяет существенно повысить скорость работы. Многоуровневая архитектура (концептуальный, ...
3. Каждая таблица должна содержать необходимые поля. Каждое поле в таблице должно содержать отдельные сведения по теме таблицы. Например, в таблице с данными о клиенте могут содержаться поля с названием компании, адресом, городом, страной и номером телефона. При разработке полей для каждой таблицы необходимо помнить, что каждое поле должно быть связано с темой таблицы. Не рекомендуется включать в таблицу данные, которые являются результатом выражения. В таблице должна присутствовать вся необходимая информация. Информацию следует разбивать на наименьшие логические единицы (Например, поля «Имя» и «Фамилия», а не общее поле «Имя»).
4. База данных должна иметь первичный ключ. Это необходимо для того, чтобы СУБД могла связать данные из разных таблиц, например, данные о клиенте и его заказы.
Стадия 3. Создание экранных форм.
Первоначально необходимо указать таблицу, на базе которой будет создаваться форма. Ее можно создавать при помощи мастера форм, указав, какой вид она должна иметь, или самостоятельно. При создании формы можно указывать не все поля, которые содержит таблица, а только некоторые из них. Имя формы может совпадать с именем таблицы, на базе которой она создана. На основе одной таблицы можно создать несколько форм, которые могут отличаться видом или количеством используемых из данной таблицы полей. После создания форму необходимо сохранить. Созданную форму можно редактировать, изменяя местоположение, размеры и формат полей.
Стадия 4. Заполнение БД.
Процесс заполнения БД может проводиться в двух видах: в виде таблицы и в виде формы. Числовые и текстовые поля можно заполнять в виде таблицы, а поля типа МЕМО и OLE – в виде формы.
VI этап. Работа с созданной базой данных.
Работа с БД включает в себя следующие действия:
- поиск необходимых сведений;
- сортировка данных;
- отбор данных;
- вывод на печать;
- изменение и дополнение данных.
3.2 Целостность баз данных
Целостность информации (также целостность данных) — в информатике и теории телекоммуникаций, означает, что данные полны, условие того, что данные не были изменены при выполнении любой операции над ними, будь то передача, хранение или представление.
В теории баз данных целостность данных означает корректность данных и их непротиворечивость. Обычно она также включает целостность связей, которая исключает ошибки связей между первичным и вторичным ключом.
Целостность данных — свойство, при выполнении которого данные сохраняют заранее определённый вид и качество.
Целостность данных
Обеспечение целостности данных гарантирует качество данных в таблице. Например, если служащему присвоен идентификатор 123, база данных не должна позволять другим служащим иметь такое же значение идентификатора. Если существует столбец employee_rating, в котором значения должны находиться в диапазоне от 1 до 5, база данных не должна сохранять в нем значения, лежащие вне этого диапазона. Если в таблице есть столбец dept_id, в котором хранятся номера отделов для служащих, то база данных должна воспринимать только те значения, которые допустимы в качестве номеров отделов компании.
При планировании таблиц имеются два важных шага: определить допустимые значения для столбца и решить, каким образом обеспечить целостность данных в этом столбце. Целостность данных подразделяется на следующие категории.
Сущностная целостность
Доменная целостность
Ссылочная целостность
Пользовательская целостность
Сущностная целостность
Сущностная целостность определяет строку как уникальную сущность в конкретной таблице. Она обеспечивает целостность столбцов идентификаторов или первичного ключа таблицы с помощью индексов и ограничений UNIQUE или PRIMARY KEY.
Доменная целостность
Доменная целостность — это достоверность записей в конкретном столбце. Она включает ограничения типа данных, ограничения формата при помощи ограничений CHECK и правил, а также ограничения диапазона возможных значений при помощи ограничений FOREIGN KEY, CHECK, DEFAULT, определений NOT NULL и правил.
Ссылочная целостность
Ссылочная целостность сохраняет определенные связи между таблицами при добавлении или удалении строк. В SQL Server ссылочная целостность основана на связи первичных и внешних ключей (либо внешних и уникальных ключей) и обеспечивается с помощью ограничений FOREIGN KEY и CHECK. Ссылочная целостность гарантирует согласованность значений ключей во всех таблицах. Этот вид целостности требует отсутствия ссылок на несуществующие значения, а также обеспечивает согласованное изменение ссылок во всей базе данных при изменении значения ключа.
При обеспечении ссылочной целостности SQL Server не допускает следующих действий пользователей.
Добавления или изменения строк в связанной таблице, если в первичной таблице нет соответствующей строки.
Изменения значений в первичной таблице, которое приводит к появлению потерянных строк в связанной таблице.
Удаления строк из первичной таблицы, если имеются соответствующие ей строки в связанных таблицах. Пользовательская целостность
Пользовательская целостность позволяет определять бизнес-правила, не входящие ни в одну из категорий целостности.
Правила целостности данных
Главная особенность SQL-технологий наличие у сервера СУБД специальных средств контроля целостности данных, не зависящих от клиентских программ и привязанных непосредственно к таблицам. Т.е. принципиально не важно, каким образом осуществляется доступ к базе данных: через SQL-консоль, через драйвера из приложения Windows, через WWW-connector из Internet-браузера или через DBI-интерфейс Perl. В любом из этих случаев, за контролем целостности данных следит сервер, и при нарушении правил целостности данных сервер известит клиента об ошибке.
К структурам контроля целостности данных относятся ограничители (constraint), которые привязаны к столбцам и триггеры (trigger), которые могут быть привязаны как к столбцам, так и к строкам в таблице.
Ограничители это элементарные проверки или условия, которые выполняются для операций вставки и модификации значения столбца. Если данная проверка не проходит или условие не выполняется, то вставка или модификация отменяется, а в программу клиента передается ошибка.
SQL-серверы, как правило, поддерживают следующие ограничители.
NOT NULL — проверка на непустое значение. NULL — специальное понятие в СУБД, которое означает «пусто». «Пусто» и «0(ноль)» не равны друг другу!
UNIQUE — проверка на уникальность. Вставляемое значение должно быть уникально для данного столбца по всей таблице. Может содержать пустые значения.
PRIMARY KEY — первичный ключ. Значение в столбце считается первичным ключом, если оно непустое и уникально в пределах столбца данной таблицы. Первичный ключ может быть составным и представлять собой комбинацию столбцов. Тогда чтобы считаться первичным ключом, каждое из группы значений не должно быть пустыми и формируемые строки значений первичного ключа должны быть уникальны в пределах таблицы. Первичный ключ — основа для построения индексов по таблице.
SQL-технология позволяет на уровне столбца задавать домены значений, т.е. строго определенные наборы или диапазоны значений, для помещаемых в столбец данных. В частности можно реализовывать ограничения ссылочной целостности (referential integrity constraint) и проверки фиксированного условия. Ограничение ссылочной целостности не позволяет значениям из столбца одной таблицы принимать значения кроме как из присутствующих в столбце другой таблицы. Это делается при помощи ограничителей FOREIGN KEY (внешний ключ) и REFERENCES (указатель ссылки).
Таблица, содержащая FOREIGN KEY, считается родительской таблицей. Таблица, содержащая REFERENCES, считается дочерней таблицей. Внешний ключ и указатель ссылки могут находиться в одной таблице, т.е. родительская таблица одновременно является дочерней.
FOREIGN KEY — внешний ключ. Назначает столбец или комбинацию столбцов в текущей (родительской) таблице в качестве внешнего ключа для ссылки из других таблиц.
REFERENCES — указатель ссылки (или родительский ключ).
Указывает на столбец (комбинацию столбцов) в родительской таблице, ограничивающую значения в текущей (дочерней) таблице.
Для использования ограничений ссылочной целостности должны выполняться некоторые условия. В частности, родительская и дочерняя таблицы должны находиться в пределах одного аппаратного сервера базы данных, они не могут находиться на различных узлах распределенной базы данных. Столбцы, участвующие в отношении ограничения ссылочной целостности обязаны иметь один и тот же тип данных.
Ограничения ссылочной целостности используются при каскадном удалении, т.е. при удалении записи в родительской таблице удаляются все записи с указанным ключом из дочерних таблиц, и наоборот при запрете удаления/модификации, т.е. при наличии зависимых записей в дочерних таблицах, значение ключа записи в родительской таблице нельзя удалить или модифицировать.
CHECK — проверка фиксированного условия. В данном ограничителе явно указывается условие, которое должно выполняться для вставляемого или модифицируемого значения в столбце. Например: check (user in ‘ALEX’,’JUSTAS’) — в столбце user могут содержаться только значения ‘ALEX’ и ‘JUSTAS’, попытка вставки значения ‘SHTIRLITZ’ будет интерпретирована как ошибочная , check (user_salary between 1000 and 5000) — столбец user_salary может принимать целочисленные значения в диапазоне от 1000 до 5000 и т.д. При формировании условий с некоторыми ограничениями могут использоваться функции, например check (user = upper(user)), в данном случае имя пользователя должно вводиться только в верхнем регистре. Есть и ограничения, например, CHECK не может содержать подзапросы (SELECT).
Обычно ограничители задаются при создании таблиц. Но в дальнейшем их можно изменять, удалять или временно запрещать при помощи соответствующих команд СУБД.
Триггеры — это сохраненная откомпилированная процедура, которая связана с определенной таблицей. Триггеры, в отличие от ограничителей, могут выполнять сколь угодно сложные манипуляции над данными. Помимо операций модификации и вставки, триггеры могут срабатывать и при удалении данных из таблицы. Можно также задавать порядок срабатывания триггера относительно операции, т.е. выполниться ли триггер перед операцией вставки/модификации/удаления значения из столбца (или всей строки) или непосредственно после такой операции.
Некоторые типовые применения триггеров:
Прозрачный аудит (не зависящий от клиентских программ и невидимый для них) и регистрация событий, связанных с доступом к определенным таблицам или столбцам в таблицах.
Генерация значений в столбцах на основе значений в других столбцах при вставке/модификации строки данных.
Манипуляции над зависимыми таблицами в особенности, если они находятся на других узлах распределенной базы данных, чего нельзя сделать при помощи ограничителей.
В случае необходимости триггеры можно запрещать, а затем разрешать. Запрещение триггеров применяется обычно при массовых загрузках данных в таблицы извне, с целью уменьшения времени загрузки. Понятие триггера как выполнение кода по событию в том же Oracle используется весьма широко. В частности, оно является основным при разработке клиентских программ при помощи SQL*Forms. Триггеры пишутся на процедурных расширениях SQL.
3.3 Транзакции
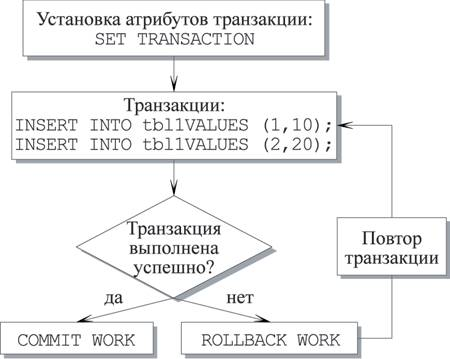
Рис 10 Новая транзакция начинается с начала каждого сеанса работы с базой данных
Многопользовательские системы широко используют понятие транзакций. Транзакция — это логическая единица работы, которая состоит из одного или нескольких SQL-выражений. Группа выражений отмеченных как транзакция рассматривается как единое и неделимое целое. В случае если в одном из выражений обработки данных происходит ошибка, то транзакция отменяется целиком. Таким образом, система возвращается в состояние предшествующее началу транзакции, обеспечивая при этом физическую и логическую непротиворечивость данных.
Например, мы пытаемся модифицировать таблицу при помощи оператора UPDATE. В одном из столбцов этим оператором устанавливается недопустимое значение с точки зрения правил целостности для этой таблицы. Срабатывание ограничителя приведет к тому, что сервер СУБД не позволит выполнить такую модификацию и известит нас ошибкой, а механизм контроля транзакций вызывает отмену всего выполняемого выражения и производит откат к предыдущему состоянию таблицы, сохраняя, таким образом, целостность и непротиворечивость данных. В данном примере транзакция работает с одним SQL-выражением. В случае если выражений несколько, то откатывается результат работы всех выражений составляющих единую транзакцию.
Чтобы транзакциями можно было пользоваться, в системе должен быть включен режим регистрации транзакций. После этого система сохраняет информацию о предыдущих состояниях объектов в системе в так называемых журналах транзакций. Журналы транзакций — это специальные файлы, управляемые сервером СУБД, в которых записываются все изменения произошедшие с момента начала транзакций для всех транзакций в системе.
Если происходит явное сохранение изменений в системе (по команде COMMIT) или неявное сохранение изменений (по завершению группы SQL-выражений, формирующих транзакцию или по завершению сеанса пользователя), то все изменения произошедшие с момента начала транзакции вносятся в систему, и информация о данной транзакции удаляется из журнала.
Для облегчения управления системой в режиме регистрации транзакций существует возможность задания так называемых промежуточных точек сохранения. Промежуточная точка сохранения по команде SAVEPOINT <имя_точки_останова> явно помечает состояние системы и предоставляет возможность восстановления состояния БД на момент ее сохранения по команде ROLLBACK. В данном случае ROLLBACK <имя_точки_останова> откатывает систему к указанной точке. Обычно промежуточных точек сохранения для одного пользователя может быть несколько.
В случае если транзакция по каким-то причинам не может быть завершена, то происходит неявный откат. Его причиной, могут быть, например, ошибка при выполнении одного из SQL-выражений, составляющих транзакцию, или обрыв связи с инициатором транзакции. При этом по информации из журнала восстанавливается предыдущее состояние объектов, которые пыталась модифицировать текущая транзакция, после чего информация о транзакции удаляется из журнала. Откат может быть и явным — по команде ROLLBACK.
Данная схема справедлива для Oracle, где транзакция начинается с выполнением первого оператора, прочие сервера могут работать по-другому. Например в Informix DS, транзакция начинается явно, при помощи команды BEGIN WORK.
В SQL-бочке меда есть своя ложка дегтя. Для всех SQL-серверов использующих журнальный режим регистрации транзакций существует проблема, так называемых «длинных» транзакций. Это транзакции, которые затрагивают очень большой объем данных (сопоставимый с количеством свободного места на дисках) и в этом случае журналы регистрации транзакций могут переполниться. Если их рост ничем неограничен, то они могут израсходовать у ОС всю доступную дисковую память, что не есть хорошо, т.к. операционная система и сервер СУБД в этом случае остаются в непредсказуемом состоянии. Если их рост ограничен, то при переполнении журналов СУБД выдает соответствующую ошибку и операция откатывается. Чтобы избежать таких ситуаций программист должен разделить длинную транзакцию на короткие транзакции.
Заключение
В моей курсовой было проанализировано создания и администрирование баз данных.
Создание базы данных стала неотъемлемой частью любой программы на нашем персональном компьютере. Базы данных имеют сравнительно низкие вычислительные мощности, это такая информационная система, создающая в памяти ЭВМ динамически обновляемую модель внешнего мира с использованием единого хранилища данных.
Базы данных решают многие проблемы:
- сокращение избыточности хранимых данных;
- а следовательно, экономия объема используемой памяти;
- уменьшение затрат на многократные операции обновления избыточных копий;
- устранение возможности возникновения противоречий из-за хранения в разных местах сведений об одном и том же объекте.
Создание столь мощного средства – не простая задача. Необходимо иметь знания в области анализирования, конструирования и администрирования БД.
Поэтому СУБД занимаются опытные профессионалы этой области, каким может стать любой терпеливый человек.
Произвольный доступ
Способ обращения к файлу, обеспечивающий прямой доступ к конкретной записи.
Ключ
Поля данных, однозначно определяющие запись в файле.
Избыточность данных
Повторение данных в базе данных.
Информационно-управляющая система
Система, обеспечивающая информационную поддержку менеджмента.
Данные
Разроненные факты
Информация
Организованные и обработанные данные
База данных
Множество взаимосвязанных единиц данных, которые могут обрабатываться одной или несколькими прикладными системами.
Система базы данных
База данных, система управления базой данных, соответствующее оборудование и люди.
Система управления базой данных (СУБД)
Системное программное обеспечение, осуществляющее управление базой данных.
Модель данных
Коцептуальный способ структурирования данных.
Иерархическая модель
Модель данных, в которой связи между даными имеют вид иерархий.
Реляционная модель
Модель данных, представляющая данные в виде таблиц.
Целостность данных
Точность и непротиворечивость значений данных в базе данных.
Представление данных
Описание ограниченной части базы данных
Доступ только для чтения
Доступ к базе данных без права обновления данных.
Планирование базы данных
Стратегическая попытка определить информационные потребности на прдолжительный период времени.
Проектирование
Операция реляционной алгебры, создающая реляционную таблицу путём удаления столбцов из существующей таблицы.
Информационный объект
Описание некоторой сущности предметной области — реального объекта, процесса, явления или события.
Атрибут
Функциональное отношение объектного множества с другим множеством.
Кортеж
Первичный ключ
Потенциальный ключ, выбранный в качестве основного средства однозначного определения строк реляционной таблицы.
Вторичный ключ
Элемент данных, задающий множество записей.
Внешний ключ
Набор атрибутов в одной таблице, составляющих ключ другой таблицы.
Отношение один-к-одному
Отношение, имеющее мощность «один» в обоих направлениях.
Отношение один-ко-многим
Отношение, имеющее мощность «один» в одном направлении и «много» — в другом.
Отношение много-ко-многим
Мощность отношения, равная многим в обоих направлениях.
Нормализация
Процесс преобразования реляционных таблиц в стандартную форму.
Функциональная зависимость
Значение отрибута кортежа определяет значение другого атрибута кортежа.
Многозначная зависимость
Ограпничение, гарантирующее взаимную независимость многозначных атрибутов.
Нормальная форма
Правила структурирования реляционных таблиц во избежании аномалий.
СПИСОК ЛИТЕРАТУРЫ
[Электронный ресурс]//URL: https://liarte.ru/kursovaya/administrirovanie-bazyi-dannyih/
Голицына О.Л., Максимов Н.В. и др., «Базы данных» (учебное пособие)
Могилёв А.В., Пак Н.И. и др., «Информатика»
Развитие технологии баз данных http://www.tisbi.ru/resource/Lib/Elbook/Access/развитие.html
Алексеев Е.Г., Богатырев С.Д. Информатика. Мультимедийный электронный учебник http://inf.e-alekseev.ru/
Зеленков Юрий Александрович Введение в базы данных. Учебный курс. http://www.mstu.edu.ru/education/materials/zelenkov/
Чертовской В.Д. Базы и банки данных http://www.hi-edu.ru/e-books/xbook099/01/